
As we continue our CampIO series, Eric Galluzzo shares how he used a generational adversarial network to write music.
He who can, does.
He who cannot, teaches.
He who cannot teach becomes a critic.
Part of our CampIO 2020 series.
In my CampIO presentation, I will show you how to teach a critic. (What that says about me, I’m not sure!) Specifically, I’ll show you what a generative adversarial network is, what you can use these for, and what my results were attempting to train one to generate music.
Let’s start with a guessing game. Which of the following people do you think are real, and which do you think were invented by a neural network? Look carefully, and don’t spoil the answer by reading past the pictures just yet.

Well, I hate to break it to you, but they’re all fake. A generative adversarial network (GAN) made all of the images above. What’s a generative adversarial network, you say? I’m glad you asked!
Generative Adversarial Networks (GAN)
GANs are actually two neural networks, trained together. The first network, called the generator, is like an artist, trying to generate the best artwork it can. The second network, called the discriminator, is like a critic, trying to determine if a piece of art is real or fake. Developers then pit these two neural networks against each other — the generator attempts to outwit the discriminator, and the discriminator tries to get more and more sophisticated so that it can discern real artwork from fake artwork.
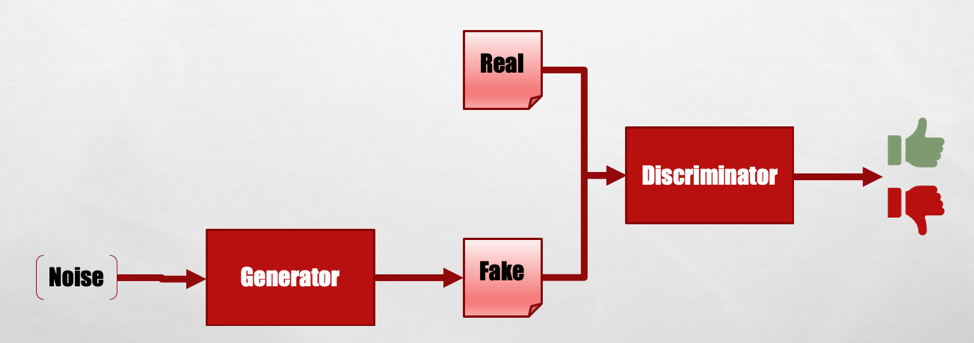
More precisely, the generator takes a vector of random numbers as input and uses it as a seed to produce a piece of artwork. The discriminator takes a piece of artwork as input and outputs the probability that the artwork is real – a number closer to 0 if the artwork is fake, and closer to 1 if the artwork is authentic. The generator is trying to get the discriminator to output all 1s based on its art. The discriminator is trying to output all 1s on real artwork and all 0s based on the generator output.
GANs can do more than generate realistic pictures (although that is what they are used for most often). They have been used to:
- “Digitally enhance” lo-res images into hi-res ones
- Interpolate between video frames – for example, turning a 15fps video into a 60fps one
- Reconstruct 3D models from images
- Detect glaucoma
- Model dark matter distribution
Why Should You Care?
- If you’re a machine learning professional in 2020, you should understand what a GAN is and how to make one. This has been one of the hottest topics in machine learning since Ian Goodfellow introduced it in 2014.
- GANs can be used for all kinds of interesting problems, as we saw above. They are most commonly used for image processing but have many other functions as well.
- They’re really cool!
Why Did I Choose to Work With GAN For a Side Project?
I don’t just write software. I also write music – both for the concert hall and also for video games. Some great engineers are trying to generate music through neural networks right now, but sometimes they are not composers themselves. As a result, their approach is not always quite in line with how musicians make great classical or film music. It also takes a long time to write good music, and my spare time is limited. So, I thought I’d try my hand at attempting to generate short melodies with a GAN. (Spoiler alert: Bach has nothing to fear yet, but I have a lot more ideas. Read on!)
How Can You Generate Music Using GAN?
If we can generate pictures through GANs, surely we can generate music as well! But to do that, we need a corpus of homogenous music. Enter the following guy.
I assure you that he is definitely not fake: this is a picture of Johann Sebastian Bach, one of the greatest classical composers of all time. He wrote 370 chorales, handily grouped into a compilation called Riemenschneider. Bach’s chorales were all very similar. He wrote each with four vocal parts (soprano, alto, tenor and bass). The structure, and the rules for the harmonies, are almost identical. Anyone who has studied music theory at college has probably had to harmonize many chorales in the style of Bach. So, these make an excellent corpus for a neural network.
Here’s one example:
Neural Networks for Music
How would we generate music with a neural network? We need to figure out the best way to represent that music and the best structure for the neural networks.
Music Representation
As it turns out, it’s pretty easy to turn music into tensors for input into a neural network. First, you quantize it into small steps (I used sixteenth notes, or semiquavers if you’re British), and then you map each note to its MIDI pitch, with -1 representing rests.

Network Representation
Almost every GAN is structured as a DCGAN (Deep Convolutional GAN). Here’s what the discriminator looks like in a DCGAN.
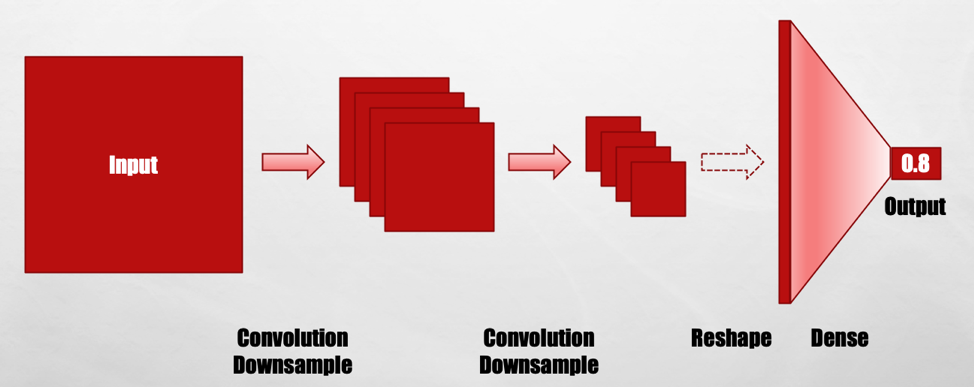
It starts with an input image, convolves it every other pixel, resulting in a stack of feature maps, and repeats the process a time or two. Then it flattens the resulting small feature maps into a big vector, which is densely connected to a single output. This result is the probability of the original input being fake. It’s very similar to a typical image classification network.
Here’s what the generator looks like.
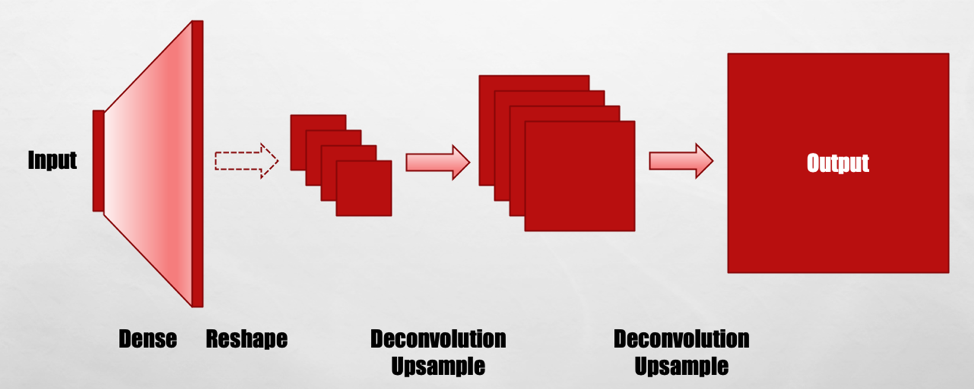
It’s basically the mirror image of the discriminator. It starts with a reasonably small vector, with a size of 50 to 100, densely connected to a wider vector. The GAN then reshapes that into a stack of feature maps, which it deconvolves and up-samples into a stack of feature maps twice as big. Then it repeats the process a couple times until you get to an output image.
Experimentation
I tried a few different models:
- Typical deep, dense network
- 1-D convolutional network
- 2-D convolutional network with one-hot vectors for each pitch
The 1-D convolutional network, with each chorale part as a separate channel, worked best for me. However, I suspect the 2-D convolutional network would work better with some tweaks.
Results
What did my 1-D convolutional network produce? Sadly, nothing very close to Bach. My favorite sample was the following:
It starts in A major, takes a detour through some very odd chords and ends up in F minor, and finally decides it wants to end in F major. It sounds more like the music of this composer.
That’s P.D.Q. Bach, the fictional 21st son of J.S. Bach — someone who was definitely working in bars far too much. 
Other Ideas
What are other ways I could improve my neural network? I have a couple of ideas.
- Conditional GANs learn to generate artwork with certain parameters (say, the time signature or key signature of the music). The discriminator can classify the music according to those same parameters.
- An embedding layer for pitches would help the neural network easily distinguish between, say, D and D# in a chord, which makes a huge difference. The trouble is the generator would also have to have a nearest neighbor (reverse mapping) layer, which is a little tricky.
Conclusion
Hopefully, you’ve learned what a GAN is, what you can use them for, how they work, and how I’ve generated some interesting music with them. If you’d like to learn more about GANs, check out the following resources.
- This Person Does Not Exist
- My code for this presentation
- Resources about GANs
- How to implement your own GAN using TensorFlow