
Snowflake Iceberg enables cost-effective data storage in open formats on cloud platforms, combining Snowflake’s query power with flexible data management. We explain in this blog.
Imagine you’re a member of the data engineering team at an e-commerce firm that specializes in diverse online product sales. Your company gathers extensive data on customer transactions, including transaction specifics, product details, and customer demographics. Typically, your company stores this data in Snowflake tables.
Snowflake offers exceptional performance and ease of use. But traditional Snowflake tables store data in the format received from the source system. This can limit interoperability with other data tools and ecosystems. And Snowflake manages table metadata within its own FoundationDB database, which potentially separates your data storage from compute resources.
You can bridge the gap between Snowflake’s familiar query capabilities and the flexibility of open data formats stored in customer-managed cloud storage.
The solution? Snowflake Iceberg tables.
Efficient External Storage Management with Snowflake Iceberg Tables
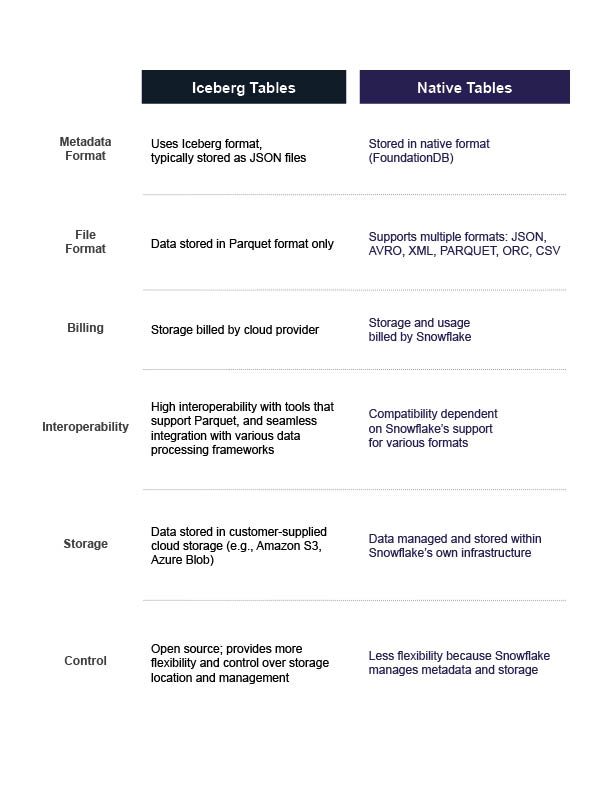
The Iceberg table doesn’t physically store your data within Snowflake. Instead, it stores data in Parquet format within your designated Amazon S3 bucket. Snowflake Iceberg manages the metadata in the cloud bucket itself, separate from the actual data in S3.
When you run queries against the Iceberg table, Snowflake translates the query and retrieves the data from your S3 bucket efficiently.
Here’s how this benefits you:
- Cost optimization: Data storage usage is billed directly by your cloud storage provider, while your Snowflake account is billed for compute and cloud services usage. This can be significantly cheaper than storing everything in Snowflake’s native tables.
- Data governance: With Snowflake Iceberg, you have complete control over the location and access of your data, which is crucial for implementing specific data governance strategies. Because the data resides in your Amazon S3 bucket, you can enforce latency requirements and implement stringent access controls.
- Seamless data integration: Snowflake acts as a central catalog that allows analysts to easily search and combine data across sources for a holistic view of customer behavior.
- Table metadata in Iceberg format: You can store data in Parquet format, a widely adopted and efficient columnar storage format. Parquet’s columnar storage and compression make it ideal for efficient data storage and processing.
- Multiengine compatibility: Snowflake can handle table management tasks such as inserts, updates, and more, allowing queries within Snowflake. Additionally, you can directly query these Parquet files using other query engines like Apache Spark, Amazon Redshift, and Google BigQuery without Snowflake acting as an intermediary.
- Performance without compromise: Snowflake Iceberg maintains the exceptional query performance synonymous with Snowflake tables, ensuring efficient data analysis. The familiar syntax minimizes the learning curve for existing Snowflake users, and you’ll benefit from the power and performance of Snowflake’s SQL engine for querying Iceberg tables.
- Custom storage pricing: As a substantial cloud customer, you likely benefit from significant storage discounts owing to extensive datasets, often spanning petabytes. You can capitalize on these existing discounts by using Snowflake Iceberg tables and storing less compressed data in Parquet format within your storage buckets.
This approach can lead to even greater cost savings compared to storing data in Snowflake’s native compressed tables, which typically incur a standard charge of $23 per compressed terabyte per month.
The bottom line: Snowflake Iceberg empowers you to harness Snowflake’s querying prowess while storing data in a cost-effective, flexible way within your cloud storage infrastructure.
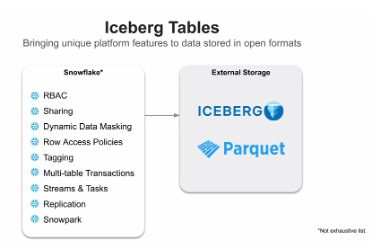
Capabilities
- Full DML support: Perform data manipulation operations (insert, update, delete) with no performance penalty compared to native Snowflake tables.
- Advanced features: Use features like multitable transactions and dynamic data masking to ensure data integrity and security.
- Row-level security: Apply row-level security policies to control data access based on user roles or attributes, similar to native Snowflake tables.
- External data utilization: Iceberg data stored in customer-managed storage can be accessed and used by external applications and tools outside the Snowflake environment.
The below figure shows the Snowflake table data in Parquet along with Iceberg metadata.
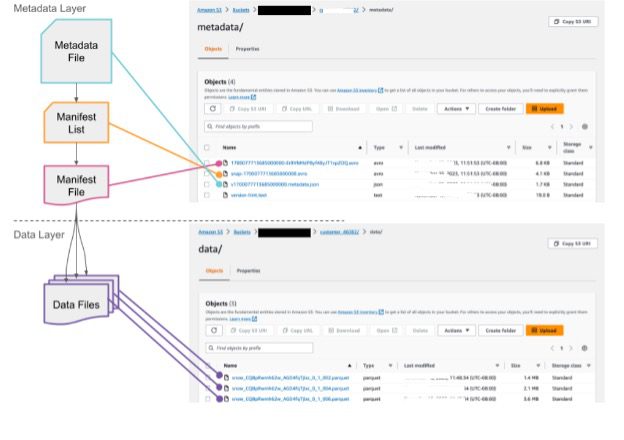
Image source: https://quickstarts.snowflake.com/guide/getting_started_iceberg_tables/index.html#0
This table provides a high-level comparison of Snowflake Iceberg and native Snowflake tables, highlighting key differences relevant to senior architects:
Harness Snowflake’s Querying Prowess While Benefitting from Efficient Data Storage with Snowflake Iceberg
With Iceberg tables, you can centralize your dataset in the cloud while also making it accessible to other systems through Parquet files or open formats stored on cloud storage.
Snowflake Iceberg empowers you to unlock the full potential of open data formats within the Snowflake ecosystem. By combining the performance and ease of use of Snowflake with the flexibility of open data formats and customer-managed storage, Iceberg tables offer a compelling solution for modern data architectures.
Want more great content like this? Check out our blog.
Are you ready to move forward with a data strategy for your organization but aren’t sure where to start? Our Data and Analytics experts bring a tried-and-true approach for executing strategies into practical, pragmatic and actionable plans. Talk to an expert


