
We know machine learning models can make your life easier, but what happens when these become less effective over time? In this blog, we discuss model drift: what it is, why it happens, and what you can do about it.
In machine learning (ML), you will hear a lot of talk about MLOps, a discipline borrowed from the more traditional IT DevOps that concentrates on delivering high-quality software development on a rapid and continual basis.
What distinguishes MLOps from DevOps and makes it a value-adding enterprise in the ML space is the former’s concentration on capabilities specific to the end-to-end ML lifecycle. This includes not only the research and development for the model but also its deployment and post-implementation support. With ML, the latter entails more than making sure your code continues to run smoothly and uninterruptedly but also monitoring and automated retraining.
You may think, “But my model is pretty good as it is. Why does it need to be monitored and retrained?”
There are all sorts of environmental factors that can cause models to become less effective over time through no fault of their own. When this happens, we call it model drift.
When you deploy a model, you implicitly assume that the statistical relationships observed between the features in your data and the outcome variable will consistently hold over time. As circumstances change – as they virtually always do in any complex system – so, too, do these relationships.
In this article, we will walk you through a real-world example of model drift. We will then discuss why drift occurs and some remedies you can explore for how to handle it within the MLOps framework.
What Does Model Drift Look Like?
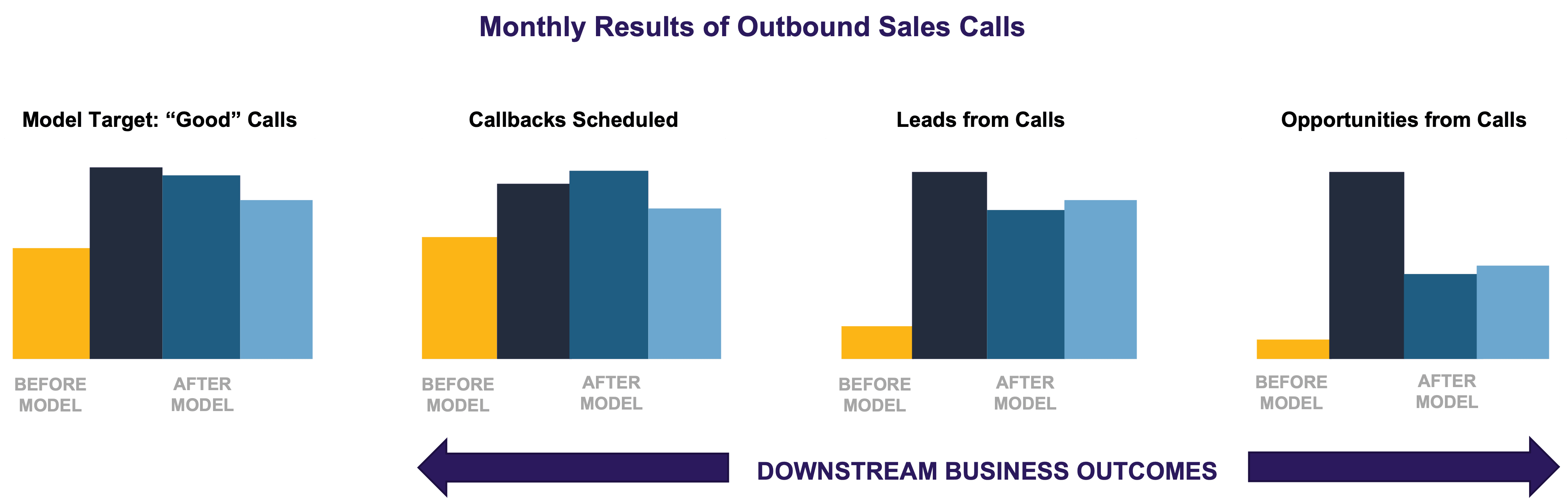
We once worked with a client to build and “productionize” an ML model for their sales call center. The goal was to increase the number of good calls their employees experienced, where they defined a good call as meeting one of several criteria, including whether the call led to the prospect becoming a lead or an opportunity.
They could then use the model output to stack-rank their list of prospects at the beginning of each day and prioritize who were the most likely people that sales members would have a good call with. Afterward, we monitored the model performance for several months and observed several interesting findings.
First, as expected, the model improved the number of good calls their sales staff experienced by over 50 percent. Second, the model began to drift within a few months of initial deployment. Third, the drift was most notably pronounced downstream when we looked at the sales pipeline to determine what calls ultimately translated into leads and opportunities. In other words, the impact of the drift visibly translated to their bottom line.
Why Does Model Drift Happen?
There are several reasons why drift can occur:
Changes to Business Processes
This could be from an improvement to technology, a desire to drive down inefficiencies, new personnel or a change in strategy. The very use of the model itself could trigger changes to your business’ status quo. For example, we once built an ML model for a client as part of their customer retention initiative, which they would use to help them identify customers proactively and talk them out of leaving. Suffice to say, the circumstances under which we trained the model ended up being different from those under which they used it.
It turns out our call center client above, shortly after their model’s deployment, had adjusted their marketing strategy to focus more on driving traffic to their website via online outlets. This was something the model would not have seen in the training data.
Changes to Target Behavior
Another one of our previous clients was working to mitigate the shortage of truck drivers in their fleet and had us build an ML model to determine who was at risk of quitting. This model quickly lost a lot of its predictive ability in 2020, however, when the landscape changed with the COVID-19 pandemic. With the closure of restaurants and facilities, a shortage of truck drivers soon became a surplus.
Changes to the Composition of the Observations Comprising the Data
If you are building an ML model to augment your marketing efforts, for example, and 20 percent of your training data comprise prospects from trade shows and 80 percent from purchased leads, much of the model’s performance will be driven by those prospects in the latter group. This can create problems if you primarily apply the model to prospects in trade shows, and those clients typically behave differently than purchased leads.
In the case of our call center client’s prospects, one reason for the drift was simply because, by design, it would pick the cream of the crop among the most promising prospects on any given day. Eventually, though, as you go down the list, you start to observe diminishing returns by dialing fewer promising candidates.
Changes to How You Collect the Data
If your model depends on select data elements, and you change the way you capture or interpret these elements, these changes can cause drift. Without retraining your model on the newer data format, it will have no way of continuing to pick up those signals.
This is a particularly noteworthy call out if you are having your data scientists hand off their code to a separate team of developers for deployment. Your model’s performance could well suffer if the latter fails to replicate the feature engineering process verbatim properly.
Whatever the reason for the drift, you have options for how to manage it that fortunately go beyond simple scrapping your model and writing it off as another lesson learned.
Retrain or Rebuild Your ML Model?
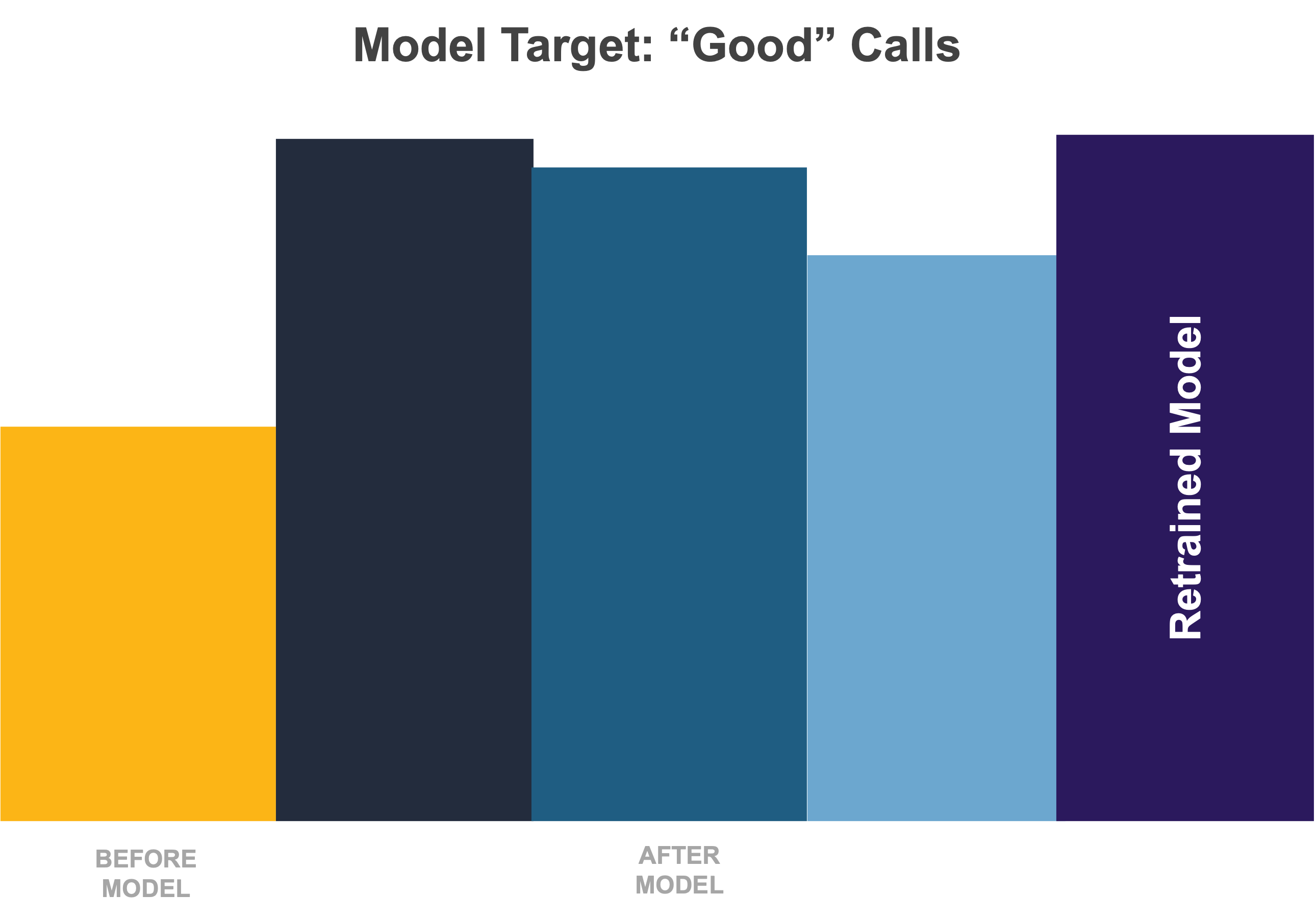
After helping you to identify model drift, your MLOps can then help you manage it. As part of its ML lifecycle, your MLOps practice should not only have measures in place for monitoring your model but also retraining it. You can reschedule the latter regularly or trigger it ad hoc under predetermined, select conditions related to your model’s performance. It should also have a process in place for comparing the newly trained model against your currently existing model.
This last step is crucial, as you can’t assume training your model on newer data will fix the problem. It’s possible that retraining your model on more recent data not only fails to provide a lift but worsens the performance. If drift persists even after retraining, it may be time to go back to the drawing board and revisit the model design methodology – the type of model you are using, the predictors you include in the model, and so on.
Once your MLOps practice has matured to a point that your retraining regimen runs like clockwork, you can automate on this front, as well. As long as you fix your selection criteria, you can set up a pipeline that compiles your training data, retrains the model, compares its performance with the current model, and uses those criteria to determine whether to replace the latter with the former.
We were able to automate our call center client’s retraining process and found using newer data could restore some, if not all, of the model’s predictive power. We even incorporated a control group into the design for better facilitating performance comparisons between competing models on an ongoing basis after that.
Do You Get Our (Model) Drift?
When it comes to MLOps, it’s all about capabilities for helping you to translate your ML insights to business value. Enabling your ML practice to not just get off the ground, but keep it there, requires monitoring and retraining as part of your process. Because in a complex world that is constantly changing, you must assume model drift as the norm rather than the exception.
With enough experience and maturity, you can codify and automate the entire cycle of monitoring, retraining and replacing your model with MLOps.
Need help determining how ChatGPT and Artificial Intelligence should fit in your organization? Make sure you aren’t left behind as companies across the globe continue to embrace these productivity enhancing technologies. In this on-demand webinar, our Artificial Intelligence expert provides an executive’s guide to what leaders need to know about adopting ChatGPT and AI in the workplace.

