
In part one of this two-part series, we described how Snowflake can help you manage modern data-storage problems. Now, we’ll take a deeper dive into the technical details.
As I explained in my previous blog, Snowflake works on a Storage and Compute separation model, which keeps the storage of data apart from its manipulation.
Now I will explore the question: How does the storage mechanism interact with the compute engine? To answer this question, let’s start by exploring three ways Snowflake manages data.
Managing Data With Snowflake
Storage
The persistent storage layer resides in a scalable cloud storage service, such as Amazon S3. This ensures data replication, scaling and availability without any management by customers. Snowflake optimizes and stores data in a columnar format within the storage layer, organized into databases as specified by the user.
PAX Architecture
- Snowflake uses a hybrid storage approach such as the PAX (Partition Attributes Across) Storage model, a hybrid of column-store and row-store.
- PAX is designed to ensure high data cache performance once the data is available from the disk. As a result, it fully utilizes cache space.
S3 Usage
- Snowflake uses S3 to store temp data generated by query operators (for example, massive joins) once local disk space is exhausted, as well as for large query results.
- Spilling temp data to S3 allows the system to compute arbitrarily large queries without out-of-memory or out-of-disk errors.
Virtual Warehouses
Snowflake processes queries using Virtual Warehouses (VWs). VWs can access any of the databases in the storage layer to which they have access, where they can perform operations such as SELECT, DELETE, INSERT, UPDATE and COPY INTO. Snowflake configures VWs only to “run” when in use. When not in use, VWs will shut down automatically after some time, so you are not charged for queries when not actively running them. Snowflake’s caching and cloud services layers further reduce the need to pay for compute time.
In my view, Snowflake’s VW architecture is one of its benefits and key differentiators because it enables elasticity, optimal execution engine storage and self-tuning and self-healing:
Elasticity
VWs make Snowflake very elastic, allowing it to manage costs while improving the user experience. For example, a data load might take 20 hours on a system with four nodes but only four hours with 32 nodes. Since the user pays for compute-hours, the overall cost is very similar, yet the user experience is dramatically different.
Execution Engine
Each VW’s execution engine is columnar, vectorized and push-based, giving it a number of advantages.
- Columnar storage and execution are generally considered superior to row-wise storage and execution for analytic workloads due to more effective use of CPU caches and single instruction, multiple data (SIMD) instructions.
- Vectorized execution means that, in contrast to MapReduce, Snowflake avoids materialization of intermediate results, which takes time. Instead, it processes data in pipeline fashion, running in batches of a few thousand rows in columnar format.
- Push-based execution enabled by this model allows relational operators to push their results to their downstream operators rather than waiting for these operators to pull data. This improves cache efficiency.
- Self-Tuning and Self-Healing mean users do not have to deal with poor performance because machine size adjusts throughout the day to match the workload. Users focus on analyzing data rather than spending time managing and tuning it.
Services Layer
The services layer is Snowflake’s “brain” and manages the complete Snowflake system — metadata, security, access control and infrastructure. This layer seamlessly communicates with client applications (including the Snowflake web user interface, JDBC and ODBC clients) to coordinate query processing and return results.
Services managed in this layer include:
Infrastructure management
- Provides centralized repository management for all storage
- Manages infrastructure by starting and suspending VW clusters as needed.
Metadata management
- Retains information about the data stored in Snowflake
- Makes it possible for new VWs to immediately use that data
- Used for Time Travel and cloning.
Query parsing and optimization
- Statistics gathered automatically
- SQL Optimizer with cost-based optimization (CBO)
- Automatic JOIN order optimization.
Security
- Accesses control for users, roles and shares
- Enables encryption and key management.
Key Features of Snowflake Architecture
Snowflake provides various unique features compared to other traditional databases:
- Flexibility to store and query semi-structured data using VARIANT
- Change Data Capture (CDC) using Streams and Tasks
- Continuous Data Protection (CDP) using Time Travel and Fail-safe
- Data Sharing with other accounts and users in Snowflake Cloud
- Results Caching
- Recovering objects using UNDROP
- Zero Copy Cloning
- Cross-Cloud or Cross-Region database replication.
Let’s take a deeper look at two of the most significant features:
Zero Copy Cloning
In traditional systems, developers had to wait hours or days to spin up a copy of a production data warehouse in a lower environment like test or development. In addition, the organization had to pay extra for disks to store all the replicated data.
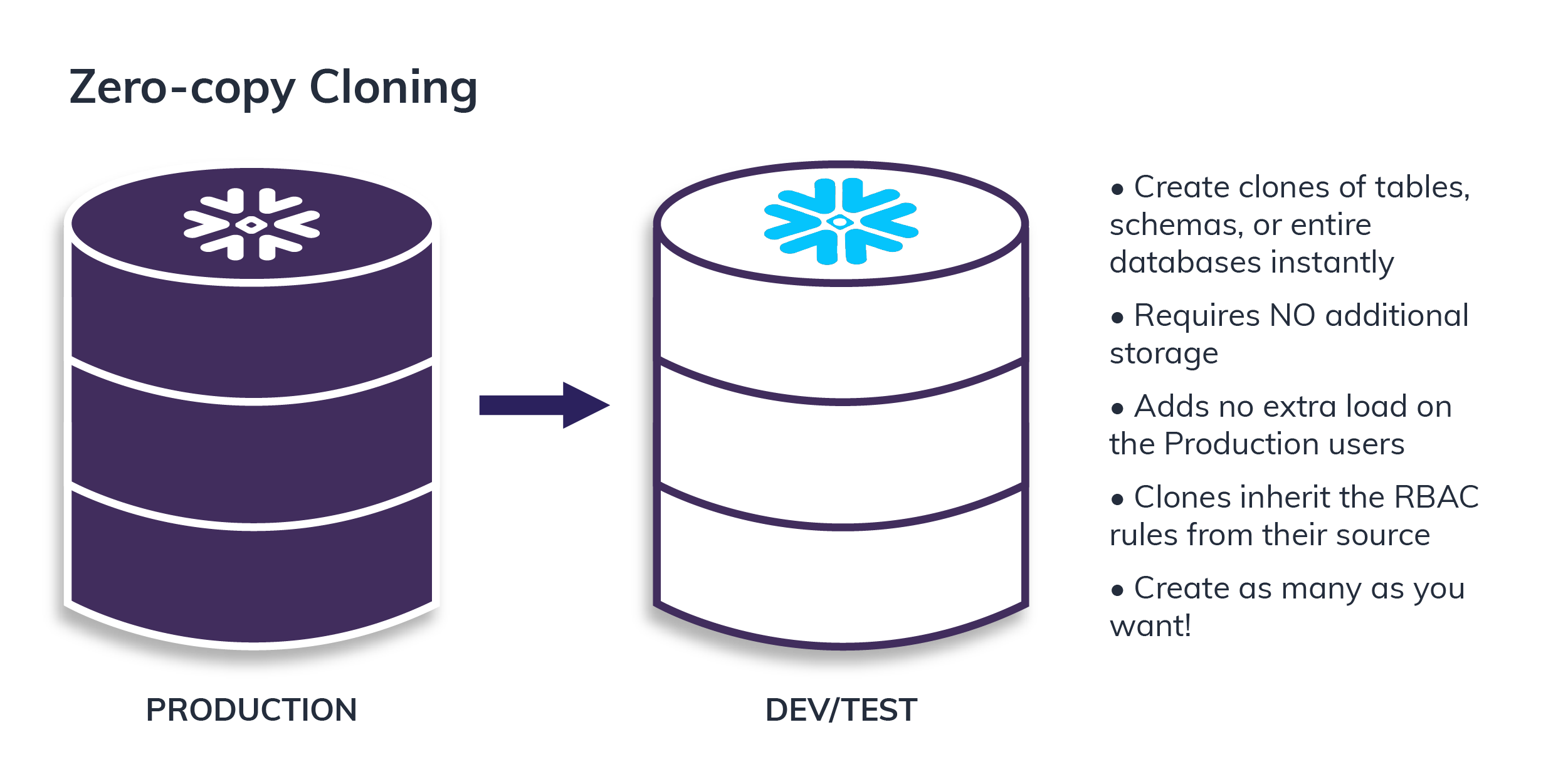
With the Snowflake CLONE command, customers can create their own tables, schemas or databases without copying the actual data. Unlike copying, with cloning the data exists in only one place and at virtually no additional cost, saving time and money.
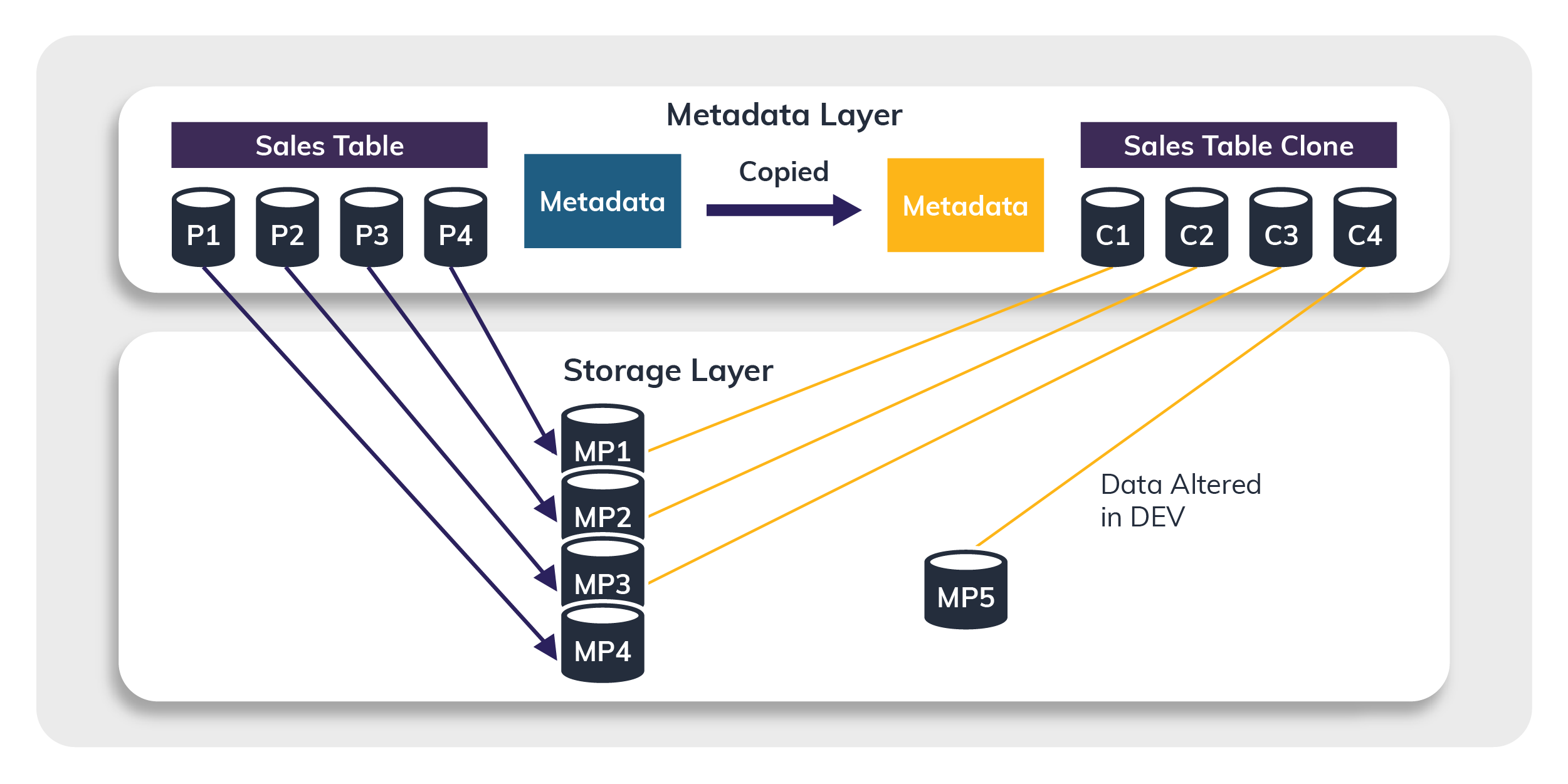
- When you execute the CLONE command, a table called Sales_Table_Clone in the DEV environment is created with all the original production data available at the time the query was run. Here, data occupies no storage space in the DEV environment.
- Updates take place inside the DEV environment on the CLONE table, which does not have any impact on production. Instead, it creates a new micropartiton in the DEV environment, and additional storage costs are levied only for the new partition but not for the complete clone.
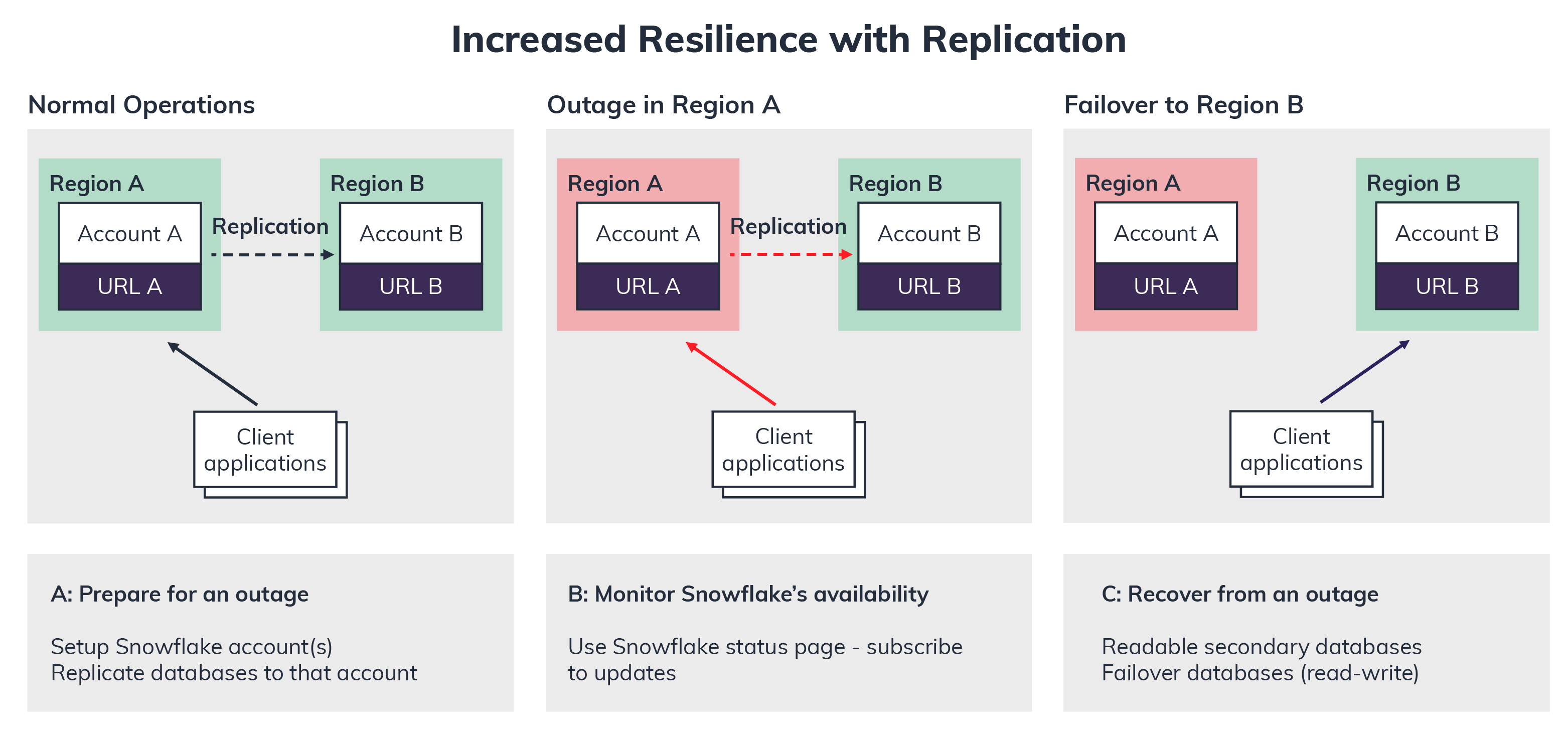
Database Replication
Snowflake can easily handle disaster management and business continuity with its Database Replication approach.

Most traditional databases require additional hardware, high cost and more time than usual to replicate data across different regions for disaster recovery and availability.
In the illustration above, with Database Replication, built-in AWS/Azure multiple availability-zone (AZ) data redundancy automatically handles a failure by default, copying data to three AZs in a region.
But what happens when an entire region fails? In Snowflake, Cross-Cloud and Cross-Region replication enable disaster recovery easily with no more than four or five SQL queries. Together, Cross-Region Database Replication and Cross-Region Database Failover mitigate data loss.
Similarly, if multiple regions experience an outage in a single cloud provider, Snowflake can deliver Cross-Cloud Database Replication and Cross-Cloud Database Failover. The diagram below depicts how easily database replication happens across the regions, and, in case of an outage for Region A, how easily failover to Region B happens.
Conclusion
With its unique hybrid architecture, Snowflake addresses all the key challenges of traditional systems, such as node failures, network failures, security concerns and support dependency. These benefits help engineers, analysts and data scientists deliver more satisfaction and easier access to their data.
In addition, Snowflake can operate at any scale of users and workloads without user and data load contention. One advantage of Snowflake architecture I see is that you can scale a single layer independently from others. For example, you can scale the storage layer elastically and be charged for storage separately. You can also provision and scale multiple virtual warehouses when you need additional resources for faster query processing and performance optimization.
Finally, because Snowflake is built for the cloud and provided as software-as-a-service (SaaS) rather than IaaS, it eliminates the need for software and infrastructure management. Its multicluster architecture allows it to handle concurrency issues so organizations can seamlessly share data without any security concerns, as the data is encrypted both in transit and at rest. And, with data availability extending across three availability zones, Snowflake can continue to operate even if two zones become unavailable.
It remains to be seen if other companies will replicate parts or all of Snowflake’s architecture, but it could be the modern data storage solution you need for your organization.
