
Snowflake’s latest updates include built-in declarative data pipelines through its dynamic tables, which allow for the automatic processing of incremental data without compromising load times. In our blog, we delve into these tables and explain how they can simplify daily data management.
Organizations that service customer data requirements often face technical challenges due to the inherent complexity of data management. These headaches can include data silos, limited scalability, the need for more efficient pipelines for data streaming and the separation of analytical and transactional data (to name a few). Snowflake, a cloud-native solution with a unique “multi-cluster” architecture, has worked wonders to address these problems with it’s latest updates. Behind its user-friendly SQL interface, Snowflake provides nearly unlimited storage and scaling capability with minimal configuration. That capacity makes it easier to collect, organize and access your data without sacrificing performance.
Now, Snowflake is providing built-in declarative data pipelines through its dynamic tables. What’s a declarative data pipeline? It’s a type of pipeline that reduces development time and increases performance by letting you focus on a desired outcome rather than the underlying mechanics.
Snowflake has also announced it will combine transactional and analytical support through its hybrid tables and offer open-format interoperability through its Iceberg Table support. Iceberg Tables will let you store large datasets used outside of your daily workloads, offering a cost-effective data retention option and the ability to securely share with non-Snowflake users.
These are only some of the enhanced features Snowflake has teased in the last year. We’re here to share the latest and greatest in Snowflake offerings and dig into the details all data engineers should know. Use this explainer to bring team members up to speed on Snowflake’s new iteration — and follow us for future updates.
The Latest and Greatest Snowflake Updates
Snowflake has expanded the platform so it can handle both day-to-day tasks and big data analysis using the same system. They also improved how the system looks and feels for users. Moreover, with the introduction of Dynamic, Hybrid and Iceberg Tables, Snowflake provides tools and tactics to simplify and streamline daily data management.
The Iceberg and Hybrid Tables are currently in the private preview stage, meaning customers need to specifically request access from Snowflake. The Snowflake Summit held on June 26, 2023, in Las Vegas, announced the preview for dynamic tables. Here’s a run-down of all the remarkable things these tables can do.
Save Time with Dynamic Tables
In Snowflake, a Dynamic Table is a table that automatically updates itself — including your logic — with the latest data as new data or updates flow into its source tables. It’s similar to a View but supports more complex combinations of underlying data than a view, with lower code complexity than a stream. This offering fixes a major pain point — Snowflake’s old mechanisms for merging and updating incremental data changes.
Today, most businesses have a real need for incremental data updates that use flexible pipelines. However, a common challenge for data engineers is knowing how to process incremental data without compromising the load times and credits of the underlying warehouse.
Yes, the old version of Snowflake provided streams and tasks to handle delta changes. However, those capabilities required extensive time and SQL knowledge to:
- Merge the incremental changes with existing data.
- Schedule the update via task to sync the changes.
On top of that, task scheduling sometimes caused process lags due to the refresh interval not being well-defined.
Data engineers would often work around these issues and process delta data by performing a full data refresh or an incremental refresh. A full refresh would truncate or drop and recreate the tables whenever you needed to consume the complete data from the source. An incremental refresh would save costs and eliminate the need to deal with high-volume data.
However, neither approach could solve for latency, maintenance issues or the costs of warehousing data. Full data refreshes also tended to hinder the scalability, time efficiency, and cost of warehousing while consuming a lot of data.
Users needed a smart, tech-driven process to identify delta changes without manual intervention. Thankfully, Snowflake’s developers delivered. Dynamic tables meet this need by providing flexibility and scalability to identify incremental data and process data streams, and you won’t have to write a single line of code.
Dynamic table features include:
- Elimination of the single-table limit in SELECT.
- Automatic processing of incremental data (in other words, these tables operate on changes since the last refresh).
- Identification of incremental changes that have happened on tables in defined pipelines without developer intervention (this allows for controlled and manageable pipelines).
- A virtual warehouse to use for all compute requirements (you can resize the warehouse according to workload).
- The ability to skip the refresh schedule if the underlying tables have not changed during the lag period.
- Replication of the entire metadata along with data during replication (compared to the former materialized views, which only replicated metadata).
- A lag setting of one minute, minimum.
The bottom line: In the past, to process delta changes, data engineers had to use streams to capture change data and tasks to automate the job. With the introduction of dynamic tables, all incremental changes are handled in an automated way, eliminating the need for streams and tasks altogether.
Syntax:
CREATE [ OR REPLACE] DYNAMIC TABLE
LAG = ' {seconds | minutes | hours | days}'
WAREHOUSE =
AS SELECT
Where:
- LAG: Defines the time interval or frequency when Dynamic table would be refreshed.
- Warehouse: User-defined warehouse based on the nature of workload.
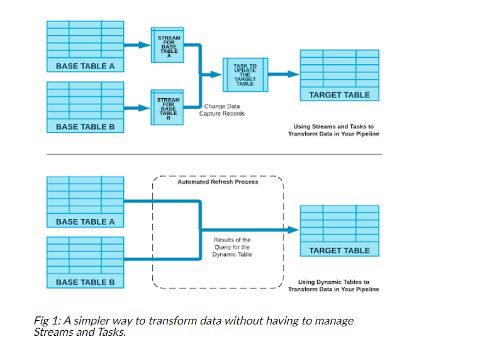
Snowflake shares a simpler way to transform data without having to manage streams and tasks. https://www.snowflake.com/blog/dynamic-tables-delivering-declarative-streaming-data-pipelines/
Reduce Redundancy with Hybrid Tables
A hybrid table is a new Snowflake structure that stores the same data for both transactional and analytical purposes at the same time, seamlessly transitioning between modes depending on the operation. Customers can now simplify their data platform, reducing pipelines and eliminating synchronization issues.
Consider, for example, an insurance company that uses both an insurance management system and an Oracle Siebel CRM application (in the claims module) to manage their data. The insurance an Online Analytical Processing (OLAP) system in Snowflake is designed to process high volumes of data with no latency. Data analysts at the insurance company use the OLAP System to derive analytical insights and make business decisions.
The Siebel insurance module within the system facilitates this process by ingesting great amounts of transactional data in real time. It takes in claims, auto policy and life insurance policy data, to name a few. The module ingests these data through quota management via issuance and maintenance.
To extend their business forecasting ability, the insurance company decides to define a model that will pull their data from the Siebel i.e., Online Transaction Processing (OLTP) system. The model will also need to collaborate with the OLAP insurance system. Altogether, the model will help to provide powerful insights about the company’s projected growth.
But the company has a problem: the data redundancy that comes with moving transactional and analytical data, stored separately, across their systems. Moreover, customers want a single place or system to store their entire data — one they can easily access.
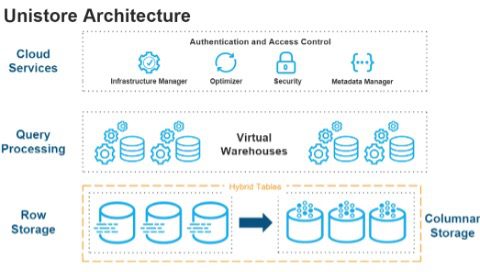
Hybrid tables (aka Unistore) solve this problem. They provide a new workload that brings both transactional and analytical data together in a single platform. Hybrid tables are exactly what the insurance company in our example needs to streamline its current infrastructure and derive effective business insights. This updated architecture provides seamless data integration and simplified data joins.
Hybrid table features include:
- The ability to generate unified data sets by bringing both OLTP and OLAP applications and data together in one place.
- An opportunity for data engineers to develop their OLTP business applications directly on Snowflake.
- The chance to perform analytical queries on transactional data in real-time and develop meaningful insights from it.
- Access to a row-based storage engine that supports fast, single-row operations for transactional processing.
- The power to continuously replicate data in the analytical store (i.e., columnar-based storage in the background).
- A direction on which storage to use to keep data under the hood.
In addition, with hybrid tables, Snowflake enforces the uniqueness of the primary index and referential integrity constraints for relationships between tables using primary keys and foreign keys. You can now join both hybrid tables and normal tables without changing any query structure.
https://www.snowflake.com/thankyou/getting-started-with-transactional-and-analytical-data-in-snowflake/
With this architecture, the storage layer brings both row and columnar storage under one umbrella. Since new features support row locking, you can perform updates more efficiently. In the background, this data synchronizes to columnar storage, which is specific to historical tables.
The biggest advantage is that it hides complexity from users. And, Snowflake lets you issue the query without worrying about how the data will be kept in the storage layer.
Syntax:
CREATE HYBRID TABLE Customers
Cust_no number (25) PRIMARY KEY,
Cust_name varchar (100),
Outstanding_Amt number (38,0),
Cust_Phone number(20)
Create the Invoice table with foreign key referencing the customer table
CREATE OR REPLACE HYBRID TABLE Invoices
Invoice_No number (25) PRIMARY KEY,
Cust_no number (25),
Invoice_Amount number (38,0),
Invoice_Status varchar (20),
Invoice_Date timestamp_ntz,
CONSTRAINT fk_custkey FOREIGN KEY (Cust_no) REFERENCES Customers (Cust_no),
INDEX ind_date (Invoice_Date));
To create a hybrid table, use HYBRID in CREATE syntax and define the primary or foreign key constraints like other relational tables. Snowflake enforces these constraints in the case of hybrid tables.
Boost Volume with Iceberg Tables
Let’s face it: You’ll need to handle large volumes of data if you want to offer effective internal analytics, gain insights into business growth potential, follow a proactive approach to customer retention, and stay competitive in general. At times, you may need to share these data with partners and research organizations. However, storing large volumes of sensitive and confidential information over the cloud — and potentially sharing it — can pose a real security challenge.
With Iceberg Tables, organizations can store big data on a cloud of their choice, like Amazon S3 or Azure Blob Storage, in the form of Parquet files. Since Iceberg supports dynamic data masking and row-level masking (all Snowflake native table features), it provides controlled access to and privacy for sensitive information.
Data is stored in customer-supplied storage, meaning multiple applications or tools outside Snowflake itself can use it. In fact, organizations no longer pay Snowflake for storage costs. Instead, the cloud providers bill for storage.
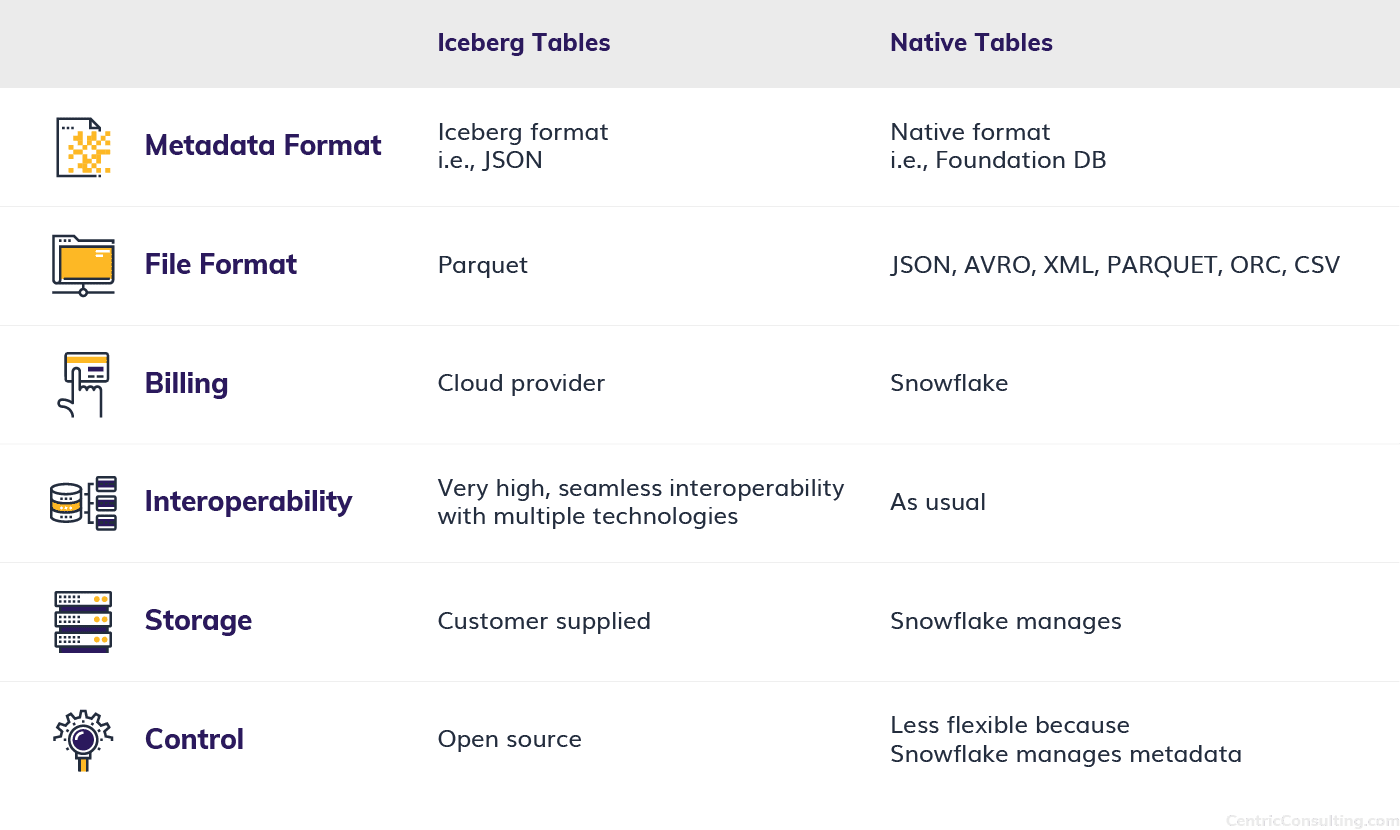
Iceberg Tables mostly work like Snowflake native tables, but there are a couple of key exceptions:
- Table metadata comes in Iceberg format, i.e., JSON, metadata and data are all stored in customer-supplied storage.
- Data is stored in Parquet files, which bring high performance and effective compression.
Know the Difference: Iceberg Tables vs. Native Tables
Syntax:
Create external volume pointing to the S3 bucket
Create or replace external volume iceberg_int
storage_locations =
(
(
name = 'my-s3-us-east-2'
storage_provider = 'S3'
storage_base_url = 's3://icebergpracticebucket1/'
storage_aws_role_arn = 'arn:aws:iam::913267004595: role/icebergrole'
)
);
Create an Iceberg Table using ICEBERG in create statement and point to external volume
Create or replace Iceberg Table customer_detail with external_volume='iceberg_int'; as Select <<col1>>, <<col2>><<coln>> from Table
Try these Snowflake Updates for Yourself
Want to know more? Take a look at Snowflake’s documentation of these new features:
- Dynamic Tables: https://docs.snowflake.com/en/user-guide/dynamic-tables-about
- Hybrid Tables: https://www.snowflake.com/guides/unistore
- Iceberg Tables: https://www.snowflake.com/blog/iceberg-tables-powering-open-standards-with-snowflake-innovations/
To conclude, each table has a unique role in business, streamlining data pipelines and automating changes with Dynamic tables. Snowflake is introducing Hybrid or Unistore tables for improved management of both transactional and analytical data. If you want to use Snowflake features while keeping data outside Snowflake, consider Iceberg Tables for tasks like Masking, Access Policies, Cloning, and more.
Data governance is essential to creating trustworthy, sustainable and repeatable value through data. What does that mean for you?

