
For this part of our CampIO series, Chris Martinez shares how he revived an old project to enhance his drone control capabilities through image recognition.
Part of our CampIO 2020 series.
For technologists at Centric, summertime has a special meaning, for this is when we hold our annual gathering of technologists called CampIO. The focus of this year’s CampIO is on artificial intelligence, or as most people refer to it, AI. AI is an umbrella term with a lot of concepts underneath it, such as machine learning, natural language processing, deep learning, and others.
With so many options to choose from, I started to think about some of my previous CampIO projects and how I could improve these with AI. The alternative would have been to pick a new project, essentially starting from scratch, which seemed less attractive. Here are a few of my previous CampIO projects for reference:
- 2019 – Run Code Without Thinking About Servers – AKA Serverless
- 2018 – Semi-Autonomous Drone Image Recognition
- 2017 – Alexa, how’s the surf?
- 2016 – The SMART Ride
- 2015 – Watch Out – A shallow dive into Apple Watch with BlueBeak
At first glance, nothing screams out AI in the list above. Alexa is definitely AI under the covers, but that stays hidden away from developers. Of the remaining projects, the one I did on drone image recognition stuck out as the best one to dust off and apply a shiny coat of AI magic on top of it.
My goals for CampIO 2020
It’s worth mentioning that, for me, CampIO is more of a journey rather than a destination. Sure, the final goal is to present and demo my project in front of my peers. But, the real value comes from learning, debugging, failing, and ultimately overcoming the technical challenges that my project throws at me. In short, here were my goals going into this year’s event:
- Continue my previous work on drones.
- Learn more about Image Recognition and AI.
- Keep my Python programming skills sharp.
- Have fun!
Refresher of my Drone Project
Before diving into what I did to apply AI concepts to my previous project, it’s worth reviewing a few of the details of that project as I delivered it at CampIO 2018. My goals for that project were as follows:
- Use an off-the-shelf drone (in my case, a Tello drone from DJI).
- Create a mobile app to fly the drone with a few simple commands:
- Take off
- Go forward
- Go backward
- Land
- Take a picture from the drone.
- Use a Cloud service to recognize who was in the picture.
My recollection of how many of these goals I met is probably overly optimistic. So instead, here are a few of the improvements I listed at the end of that presentation:
- Image Recognition is a little slow.
- Drone controls are a little twitchy.
- I need to add Video API for more autonomous flight control.
These improvements have AI written all over them. That’s where I’ll dive in next.
New and Improved Drone Flight Controls
One of the biggest challenges with my previous project was that I needed both hands to hold the mobile phone to fly the drone and tell the drone to take a picture. I had to do it this way because there was no video interface from the mobile app to the drone, essentially rendering the mobile app blind to what the drone camera saw.
My plan an ambitious one: use the video from the drone camera to recognize a few human-shaped letters to control the drone. Think about everyone’s favorite dance song at a wedding, YMCA, and you get the picture. In my case, a human forming an “A” meant “go forward,” a “T” meant “go backward,” and a “W” meant “land.” This would take many steps to achieve my plan.
Step 1 was to add video capabilities.
Adding Video Capabilities
Two years is an eternity in technology, and this was true for the video capabilities of my drone. More specifically, after a few firmware updates and a new SDK, I was able to pull a video feed in real-time from the drone down to a Python app running on my laptop. This meant that while the drone was flying, my app could now see what the drone camera saw. With that baseline established, the real AI work could get started.
Real-time Image Recognition
As I mentioned above, my previous project already could do flight control in real-time with simple commands like:
- Take off
- Go forward
- Go backward
- Land
Now that I had a live video feed, the next step was to inspect the images in the video and recognize the A, T, or W human-shaped letters. This represented the deep end of the AI pool, at least for me. In reality, this step involved multiple tasks:
- Creating a Neural Net to recognize human-shaped letters
- Training the Neural Net to recognize the human-shaped letters
- Publishing the Neural Net model for real-time classification
- Drawing a skeletal overlay onto the video using landmarks.
Creating a Neural Net
Let’s start with the first task: creating a neural net to recognize human-shaped letters. Luckily, I did not have to start from scratch on this task as I was able to find an existing platform called Caffe Deep Learning Framework that did most of the heavy lifting. Caffe is a neural network-based framework geared towards image classification and image segmentation. Caffe has a Python API that slotted in nicely with the app I created to capture real-time video.
Training the Neural Net
Once I had the basic neural network created, the next step was training the network by feeding it multiple images of the representative “A,” “T,” and “W” human-shaped letters. Again, Caffe provides the tools needed to run through the images and train to the desired accuracy. All I had to do was contort myself into the various poses for A, T, and W letters and then feed them to Caffe.
Publishing the Neural Net
With training out of the way, the final task was to publish the Caffe model so the drone could classify images in real-time. This essentially means “freezing” all of the weights in the neural net and creating an API that accepts an image and returns a letter A, T, W, or None. Once again, Caffe provided this publishing mechanism to a Python file that could be imported directly into my application.
Drawing the Skeletal Overlay
The last task in the AI journey was to identify and display an overlay of “landmarks” that help the user visualize the letter they are trying to form. To do this, I used a popular open-source library called OpenCV, specifically the Python version of OpenCV. With OpenCV, I was able to convert the video frames into images, identify the landmarks in the image, and draw the overlay onto the live video stream. The photos below show a template of the skeletal overlay and live image:
0. Head 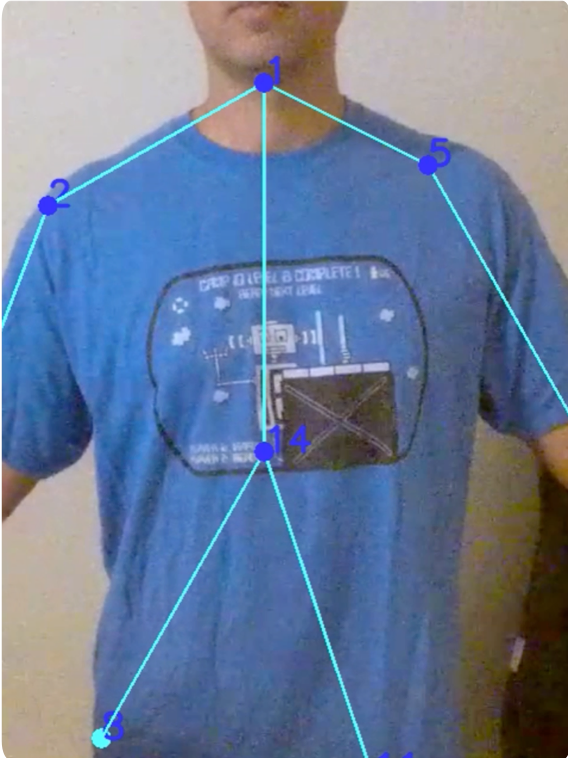
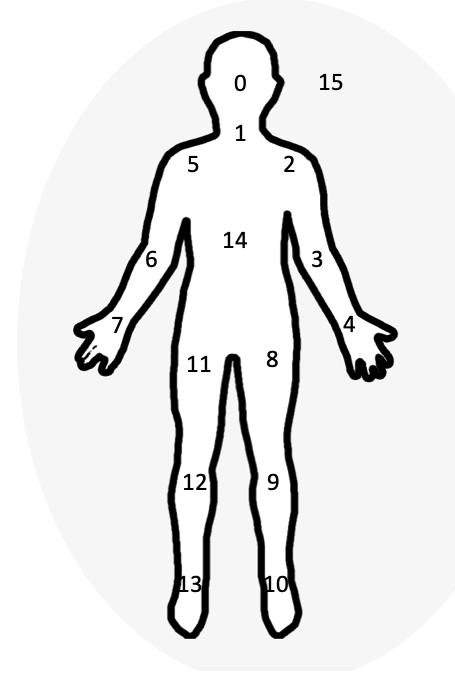
1. Neck
2. Right shoulder
3. Right elbow
4. Right wrist
5. Left shoulder
6. Left elbow
7. Left wrist
8. Right hip
9. Right knee
10. Right ankle
11. Left hip
12. Left knee
13. Left ankle
14. chest
15. background
Bringing it all together
With the AI tasks finished, the final step was to bring it all together in a single app. The Python app ties the following tasks together:
- Human-shaped letter
- Model training
- Video processing
- Video to image
- Identify landmarks
- Draw skeleton overlay
- Image recognition
- Caffe model response
- Flight control
- Tello socket interface
Results and Lessons Learned
After several attempts and one crash landing, I was able to successfully control my drone with no hands, only human-shaped letters. In the process, I learned quite a bit about AI, specifically image recognition. There are lots of great tools out there that helped accelerate my approach, most importantly Caffe and OpenCV. Here’s a quick summary of my results and lessons learned:
Results
- The drone survived.
- No humans or animals were hurt.
- I was able to link the video from the drone to the application.
- I needed an AI model for mapping human-shaped letters to classifications.
- Image recognition led to controlling the drone.
Lessons Learned
- A lot of off-the-shelf components are available for image processing and AI.
- Flight stability made recognition unreliable.
- Remembering which human-shaped letters mapped to which flight controls proved to be a usability challenge.
- The journey was far more fulfilling and meaningful than the destination.