
This post is part of our blog series to explain the challenges involved with developing a mature machine learning environment. We will discuss the first portion of the ML lifecycle of model research and development.
In a prior post, we discussed MLOps: how we think about it and the value proposition such a framework buys you. We talked about end-to-end capabilities and processes and enhancing the machine learning lifecycle.
But what exactly do we mean by the machine learning (ML) lifecycle? What end-to-end process do we have in mind?
At a high level, the lifecycle, shown in the figure directly below, comprises three main components: model research and development (R&D), the retraining cycle and management and infrastructure. The first is key for taking your model from an abstract idea to a tangible, final product, the second for maintaining the final product, and the third for enabling the former two as effectively and efficiently as possible.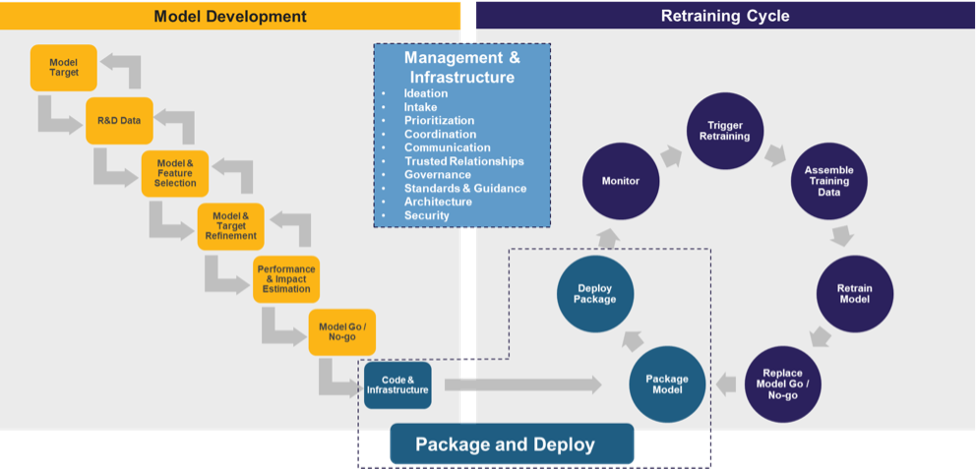
While the outlined steps in the above diagram may seem straightforward, in a complex arena like data science, the devil is in the details. In this article, we will unpack the steps underlying the first component – model research and development – where cutting corners in the name of getting your minimum viable product out there can put you at the particular risk of jeopardizing the value proposition of your initiative entirely.
Researching and Developing your Machine Learning Model
The below figure provides a “zoom in” of the “Model Development” component of the ML lifecycle, shown previously above.
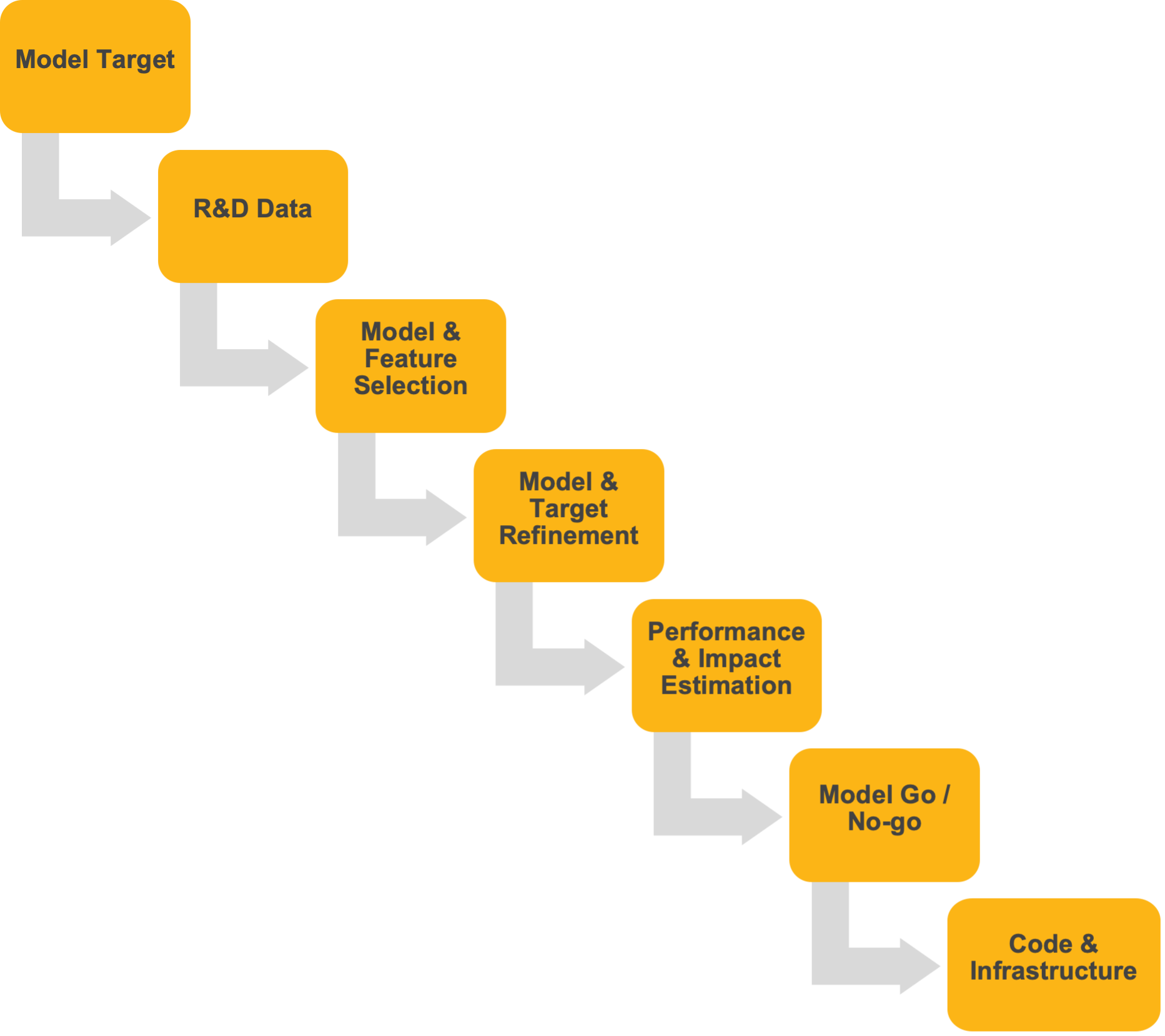
You can conceptually think of model research and development (R&D) in linear terms – sequential in nature with iterations between select steps. We are going to assume, for the purposes of this discussion, that you have already decided on an ML model to work on, presumably via an intake process by your team. Suffice it to say, though, that intake and model ideation are processes that warrant additional discussion as they relate to the management of your ML lifecycle.
In other words, in the context of this blog, your organization has a mature demand intake process for resolving business and functional challenges by leveraging artificial intelligence and machine learning (AIML) solutions.
Model R&D comprises the following steps.
Model Target
First, you need to determine what the model is specifically going to do. This might seem straightforward once you’ve identified the use case, but it can get complicated quickly. It’s one thing to have a model for solving a business problem, but how exactly are you going to apply it? Oftentimes, there are different ways to think about and quantify an outcome. This is where it is important to work closely with your end user to understand not only what they say they want to be done but to distill from that what they really are trying to accomplish.
That means understanding how they intend to use the model in practice. For example, are you trying to predict product demand, forecast weather impact on yield, or do you want to gauge the impact of a global conflict on your supply chain and associated prices? This is especially crucial in applications where current KPIs are not telling the full story. What on the surface might sound like a use case for a linear regression forecasting problem may, upon further refinement, amount to a classification problem. In addition, this may be a good time to think about how you will ultimately deliver your model to the end users for consumption.
R&D Data
Once you define your model target, you need to take an inventory of what data you may want to use to develop your model. This means working with the business and your IT partners to identify what source datasets they already have readily on hand and what additional data you could bring in, either from public or proprietary sources.
Depending on your situation, you might need to pause here, so you can develop a more mature data-collecting process. If your model is part of a larger initiative to automate a process, for example, part of the solution may entail building a robotic process automation (RPA) tool that can fetch the data humans are currently manually collecting.
You will also explore the quality of your data during this phase. This includes checking for collinearities, identifying outliers and missing data, and developing a strategy for how to manage them when the time comes for modeling.
When compiling your input data, you will also have a forward-looking eye out for future end-state, automated data pipelines and how you would go about tying these inputs together for if or when the time comes to productionize the model. While it perhaps goes without saying, there is no point in bringing features into your assessment you have no hope of supplying these on a recurring basis.
Note the iterative nature of R&D, as shown by the arrows on the above diagram. When we talk about data, this includes the model target – arguably the most important column of data you want to research during this phase. You may walk out of a meeting with the business with a clear definition and agreement as to what the model target should look like, where to get the data and how to calculate it, but upon further exploratory analysis conclude it’s not the right outcome to predict.
Maybe you are trying to classify text data, only to conclude there aren’t enough records to build a satisfactory model. Or, maybe there are data quality issues: perhaps the outcome variable is not well measured or there is a lot of missing data. Predictive models require variation in both the outcome you are trying to predict and the predictors associated with them, and maybe there is not enough variation to detect the signals needed to perform the task at hand.
It’s also very possible as you are doing analytics, you learn new things about the target outcome your consumer wasn’t aware of. Whatever the reason, you may find something that compels you to go back to your business partners and revisit the use case.
Model and Feature Selection
Now that you have explored your data, it’s off to the races. This is where you will do your experimentation and identify what algorithms to use. It’s one thing to do a classification problem but what kind: Logistic regression? Decision tree? Neural net? And for any of those models, what are your hyperparameter values? The nice thing is, you don’t necessarily need to make that decision yourself as you can put them all up against one another. It’s possible, at the end of the day, you don’t even have to choose but find that an ensemble model works best.
In tandem, you will also do more work to refine what attributes collected during the prior step you will ultimately factor into the model. Oftentimes, attributes will not be directly available from the data, in which case you must engineer these.
Depending on the amount of data you have and the number of columns you are putting in, you may need to think through measures to reduce the number of predictors you put into the model. This could include dimension reduction techniques. Though you may wait to see how your model performs to see if you can drop any based on their poor predictive performance.
Model and Target Refinement
It’s possible – after selecting your model, tuning your hyperparameters and selecting your variables – your model still does not perform to the level of satisfaction required for your user’s needs. You might salvage the project by finding a niche that adds value. In which case, you may need to go back to your business partners and renegotiate what you are targeting, who or what you will apply to, how it will be used, and so on.
Performance and Impact Estimation
How does your model perform, and how does it translate to bottom-line business outcomes? What subsets of the data exhibit signal? You may need to enlist some additional measures, such as A/B testing, to shed further light on this, as A/B testing allows us to understand how an altered variable affects the outcomes.
Model Go or No Go
With all the numbers at hand, it’s time to determine whether to undergo the effort of productionizing your model. This includes refining your data pipelines and readying them for automation, developing scoring scripts and building out an infrastructure that integrates your model into the applications consuming its output.
Code and Infrastructure
It’s go time! You can think of this step as the bridge between the development and retraining processes and as part of your efforts to package and deploy the model. This step is also where MLOps overlaps extensively with DevOps. As part of this effort, you need to make sure you modify your applications to ingest the model results and put them somewhere people will use them.
Depending on your needs, you might stand up services to host the model. You might also have to assemble database pipelines to process scores or data used by the model. Pre-work to understand your application development environments, testing requirements and release schedule among others will make sure model outputs are deployed and consumed as per plan.
As part of this, you will also need to develop an architecture for logging model activity. This includes recording the inputs that are fed into the model, the scores the model generates for those inputs, and when those scores were generated. These components will be critical ingredients for implementing the second major component of the ML lifecycle: the Retraining Cycle.
AI is rapidly evolving beyond the familiar chatbots. While many leaders use tools like ChatGPT to increase productivity, AI agents will transform how businesses operate entirely. If you want to stay ahead in the AI arms race and drive significant returns, this executive session is for you
Conclusion
In this article, we’ve introduced you to the ML lifecycle, the paradigm underlying MLOps which guides you on how to think about translating your ML model into a valuable and viable, proposition. We then unpacked the first of three major components: the model research and development – walking you through the end-to-end, high-level process – from determining exactly what your model is going to do to getting your final product ready for production as well as all the steps between.
It’s one thing to build a value-added model. It’s another, however, to maintain that value, particularly in the face of model drift. In a future post, we will talk more about the next phase of the ML lifecycle, the Retraining Cycle, which addresses that.

