
In this three-part series, you’ll learn the process of selecting a tech stack for a project.
Blog three of a series.
Choosing the right libraries is a necessary part of every project, regardless of the programming language. Ideally, the bulk of a project can be completed using native libraries.
But external libraries become a requirement as soon as you introduce a data source, socket communications, or testing.
Library Proliferation
For any language that has been around for a while, like C#, Python or Javascript, there are sure to be many choices for each type of need. Fragmentation increases as the number of developers jump on to the bandwagon and have their own twists on how to solve common problems.
Here is where experience in dealing with open source type applications comes in to play.
How do you identify which third-party libraries are most likely to bring a positive impact to the project?
Consider the following: popularity/community, ease of integration/use, availability of examples or track record, support by the primary developer, and “fit” with regards to the philosophy of the project.
One indicator of a critical mass of a language is when the large vendors start supporting it either as a main offering or as an “official” access language for their own products.
As an example, when developing various cloud platform services, JavaScript running on Node.js is typically one of the first, if not the first, development environment supported.
Some examples of this include:
- Google’s Cloud Functions
- Amazon Lambda & ElasticBeanstalk
- Heroku
- Cloud Foundry
- IBM BlueMix
- Facebook’s Messaging Platform (examples are in Node.js)
Given that companies typically treat Node.js as a first-class citizen, vendor support for connection libraries (i.e. databases, queues, mail provider) will either directly provide libraries or copious amounts of instruction in how to make their products work with Node.js. This makes it easy for us to recommend for client usage.
But, in actual practice, there are very few critical libraries that are usually required on a project. A connection to the primary and secondary databases, a cache server, a services framework, and a queue engine all have major vendor support for all the languages listed above.
If there are critical needs to your application – like a math library around matrices or a viable third party library that your target language does not have – then you might have selected the wrong language.
Availability of Developer Resources
I typically don’t put much credence in job surveys because it doesn’t take into consideration the type of work being requested.
For example:
- R, listed below, is in the 8th spot but is not considered a general purpose language , but rather a language for data processing/analysis.
- C & C++ are typically required in more scientific, hardware-related, and other areas where speed and complete control over the hardware environment are paramount concerns.
- PHP, Scheme, & Perl each have different strengths that would not be viable for overall application foundations , but may be used for spot needs as a supporting utility language.
Thus the popularity of 6 of the top 10 languages (in this survey) are not commonly relevant to our situation most of the time because most business applications do not contain the types of problems for which those languages were designed.
So when determining language popularity and developer demand, make sure considerations are being given to those choices that are contextually relevant. The point is that some of the languages you do not see in the top 10 can be more capable of solving your problem than those that are.
Additionally, these types of surveys only look at the /demand/ side of the equation and do not speak to the actual supply side. The reality is that there is a skills gap across the board.
For languages like C# and Java, it’s typically more cost-effective to search and buy (or steal) resources, but for many of the other languages (including both Python and Javascript) it can be more productive to build them.
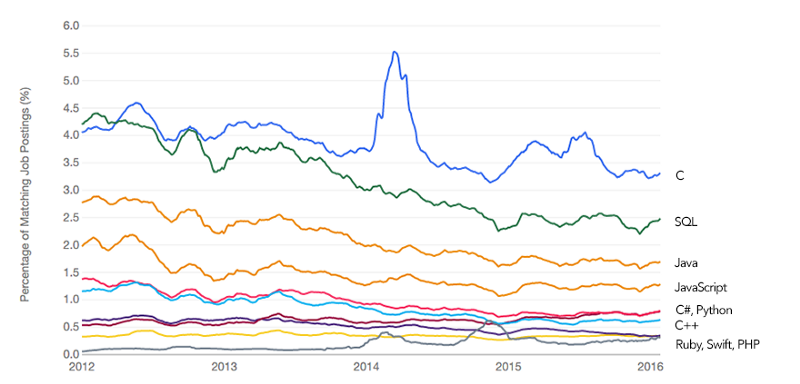
Do you think the general trending downwards is indicative of programming language proliferation or specialization?
Nevertheless, these are the top 10 “in-demand” technologies according to site point based on the frequency of technologies appearing in job postings.
See: Best Programming Languages For Job Demand and Salaries, 2015
- Java — featured in 18% of advertisements
- JavaScript — 17%
- C# — 16%
- C — 9%
- C++ — 9%
- PHP — 7%
- Python — 5.5%
- R — 3%
- Scheme — 3%
- Perl — 3%
For more detailed information about various different metrics and how they are determined, this link has several different metrics of language popularity: What’s the Best Programming Language to Learn in 2015? or also here.
But, the most appropriate quote from this article and the sub-text of many others is this:
Those who pick a language based on survey data or monetary prospects will fail.
This is true when selecting a stack for a project based solely on graphs and charts as well as when looking for a job.
Summary
We select our stacks based on the experience we have using these technologies to solve similar types of problems to those presented by the project at hand.
Because of the way we typically design systems, “swapping” out smaller applications will negate the need for performing any type of wholesale overhaul to upgrade specific functionality. In other words, n monoliths.
A new application is meant to be scale-able and agile in both development and operation. The purpose of this is to avoid the need to “have to live” with our decision for the next decade because it is too painful to maintain or replace.
In the end, it comes down to the problems we are trying to solve. Because I’m a polyglot proponent, I come down on the side of the “right tool for the right job.”
Since most of my recent projects involve many small sets of standalone services, the stack selection exercise can be performed over-and-over as new modules are brought online.
A stack suitable for one module might be completely ill-suited for the next.