
Before you purchase and use Microsoft Fabric, you need to understand how to calculate your potential Microsoft Fabric costs based on usage. Here’s how.
After Microsoft introduced Microsoft Fabric, a Microsoft-unified software-as-a-service comprehensive data analysis platform, it sparked widespread exploration. However, due to its diverse array of features, creating a business strategy and developing an effective solution requires you to have a solid foundation of knowledge about the platform.
Before your business opts to purchase and use Fabric, you will need to grasp its essential functions and understand how to leverage it for efficient data usage within a strategic cost structure. After reviewing Microsoft’s latest updates (as of the time we published this article), we have simplified the parameters organizations can use to strategize their usage consumption when building their analytical solutions to streamline their Microsoft Fabric costs.
Note: In this context, “usage consumption” refers to how much an organization uses Fabric’s resources — such as data storage, processing power, or analytical tools — to build and run analytical solutions. This definition accounts for both how efficiently organizations consume these resources and the costs associated with their usage.
Before we dive into how different workloads or functionalities consume resources under Microsoft Fabric, you need to first understand how Microsoft evaluates cost based on usage.
Real-time data should drive decisions, but complexity and cost get in the way. Microsoft Fabric’s Real-Time Intelligence eliminate these barriers, bringing enterprise-grade data analytics within reach. Watch our on-demand webinar to discover how Fabric RTI can transform your organization’s approach to live data.
Microsoft Fabric Cost: Usage Elements
In Fabric, every analytical system includes both a storage layer and a functional component. Fabric, as an all-in-one analytical solution, integrates these elements seamlessly, spanning from a universal storage layer to data movement, data science, real-time analytics and business intelligence capabilities.
For consumption, Fabric defines two distinct yet essential consumption parameters for both data and functionality:
1. Storage
Any data residing in the Fabric-enabled tenant lake, a single instance of Fabric for an organization, incurs a cost. Fabric offers a universal layer for storing your entire organization’s data, serving as the provisioned single storage service for all workloads and functionalities. Additionally, it allows you to natively link your existing third-party storage systems, making them available for Microsoft Fabric analytics workloads for any analysis of data residing outside of Fabric.
2. Capacity Units (CUs)
Under the hood of Fabric, different functionalities rely on processing and compute power to perform their tasks, much like how the CPUs of a computer handle various operations. In Fabric, this processing power is measured through compute units (CUs) that measure the compute power available for different workloads.
Fabric offers these resources under its various SKUs or packages of resources tailored to your organization’s needs. Each SKU provides a certain amount of computing power and memory, and your business can choose the SKUs that best match your data needs and budget.
To access these resources, your organization will need to purchase capacity licenses. Each license offers a selection of SKUs, each providing different resource tiers for memory and computing power. Based on your business requirements and capabilities, your organization can opt for one or more capacity licenses, ranging from the lowest, F2, to the highest, F2048.
Workloads or functionalities have diverse ways to consume and calculate storage and CUs, and you need to understand some of the most common ways as you determine what your Microsoft Fabric costs could be.
Functionality Consumption
For each Fabric functionality, we describe the consumption of these elements. Based on each workload, organizations can formulate their consumption strategy and calculate costs using the parameters and functionalities outlined in the Microsoft Fabric use cases below.
OneLake: Storage for Your Entire Organization
OneLake storage serves as the sole storage layer for the entire organization tenant, or all the data within your organization’s Microsoft Fabric environment, with consumption usage defined in terms of both storage and CUs.
- Data storage: Any data residing in OneLake is billed at a pay-as-you-go rate of $0.023** per gigabyte (GB) used by Fabric-related items such as Lakehouse and Datawarehouse. This storage cost for consumption is separate from processing costs associated with the capacity licensing. It’s important to note that for “soft delete” data — data temporarily deleted but not permanently removed — you will still be charged for OneLake storage for the deleted workspace or files during the retention period. This period can be configured from 7 to 90 days and a default of 28 days.
- CUs: Any requests to OneLake, such as reading or writing data, will consume Fabric CUs. For both types of transactions, the consumption of CUs varies based on whether it is called from inside Fabric platform (redirect) or from outside Fabric (proxy) as described in Table 1 below.
These two scenarios will affect how much of your resources are used, so it’s crucial to factor that into your overall resource planning. As Table 1 illustrates, external Fabric transactions consume approximately three times more CUs for reading and about twice as many for writing compared to internal Fabric transactions.

Disaster Recovery Storage
OneLake uses advanced storage methods to ensure your data is safe and resilient against hardware failures. For instance, it offers zone-redundant storage (ZRS), which means your data is copied synchronously across three Azure availability zones in the same region, providing excellent protection. It also uses locally redundant storage (LRS), which replicates your storage account three times within a single data center in the primary region, ensuring data resilience against transient hardware failures within that location.
To further protect your data from rare but serious region-wide outages, you can consider implementing a disaster recovery solution. You can set up a disaster recovery solution through the Capacity Admin Portal in Fabric. Once enabled, the data in OneLake gets geo-replicated for that specific capacity. Geo-replica copies your data synchronously three times within a single physical location in the primary region using LRS. It then copies your data asynchronously to a single physical location in a secondary region that is hundreds of miles away from the primary region for the specific enabled capacity.
Like OneLake usage, its billing is also defined by the amount of data stored and the number of transactions. However, when it comes to disaster recovery, data storage is billed as Business Continuity and Disaster Recovery (BCDR) storage. For BCDR, the minimum OneLake storage per month is billed at $0.0414** per GB.
The CU for BCDR Operations is the same as OneLake read consumptions for read transactions. However, since it requires writing to more than one location, the consumption increases for write operations only, as illustrated in Table 2.

Table 2. CUs Usage by OneLake Operations for Disaster Recovery
OneLake’s Shortcuts and Fabric Mirroring
When accessing data in OneLake from locations other than its original source, the following two concepts, shortcuts and mirroring, come to the rescue.
- Shortcuts allow us to create live connections between OneLake and existing target data sources, whether internal or external to Azure, without replicating the data.
- Mirroring, in contrast, replicates near real-time data from external sources to OneLake with automatic synchronization with the target.
Table 3 illustrates the high-level description and differentiation between the two:
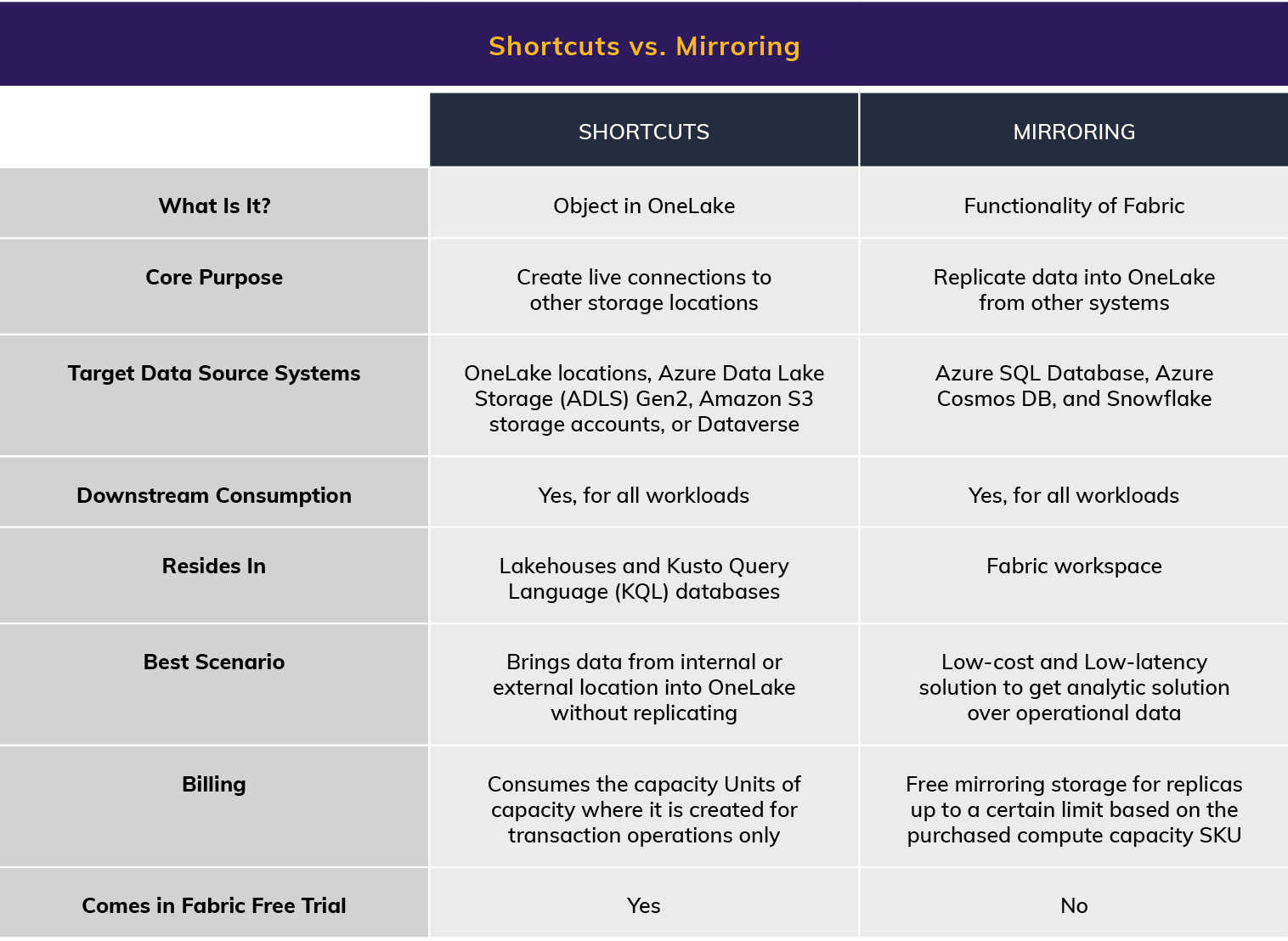
Table 3. Shortcuts vs. Mirroring
Workload Consumption
A single data layer alone does not suffice for Fabric to function as a complete analytical solution platform, which is why it includes many other functionalities. Let’s talk about the consumption of each major functionality, known as a workload.
Since all these workloads perform actions on data stored in OneLake, Microsoft will charge any data storage and read/write operations according to OneLake standard storage charges or cache charges, if applicable.
In terms of CUs, Microsoft charges each workload based on their specific operations. That means each action performed by a workload will impact your resource usage and overall Microsoft Fabric costs. Here are the major workloads to know about:
Fabric Data Factory
Unlike Azure Data Factory, which is a platform as a service (PaaS) or an independent service for data integration, Fabric Data Factory is a SaaS, meaning it is better integrated with other parts of the unified data platform, including Lakehouse, Data Warehouse and more. It provides serverless and elastic data integration service capabilities built to handle cloud-scale workloads.
Fabric Data Factory provides two ingestion methods to bring data into the Fabric platform:
- Data pipelines
- Dataflow Gen2
While these two methods differ in their technical architecture, they both consume CUs for processing, meaning Microsoft calculates resource usage similarly, regardless of which method you choose.

Table 4. CUs Usage by Fabric Data Factory Operations
Fabric Synapse Data Warehouse
Fabric provides a lake-centric virtual data warehouse, Synapse Data Warehouse, that incorporates data from any source using shortcuts This warehouse supports atomicity, consistency, isolation and durability (ACID) transactions. The warehouse also supports cross-engine interoperability, such as the ability to use Spark, Power BI and other Fabric components to directly connect to it in addition to SQL.
In terms of CUs, running compute operations in the Data Warehouse consumes resources. One unit of compute for a Data Warehouse is equivalent to two Fabric CUs.
These units are consumed during the following Warehouse operations:
- Warehouse query: All T-SQL queries generated within a Warehouse
- SQL analytics endpoint query: All T-SQL queries generated within an SQL analytics endpoint
- OneLake Compute: All reads and writes for data stored in OneLake
Since each operation’s consumption is based on query execution that utilizes Warehouse vCores, there is no specific standard consumption rate.
Real-Time Intelligence
Fabric’s Real-Time Intelligence offers powerful tools for gathering data insights and visualizing data in motion related to event-driven scenarios, data logs, and streaming data.
It contains two components:
- Event streams
- Kusto Query Language (KQL) database and KQL query set
Both components consume CUs as per their operations, as illustrated in Table 5.
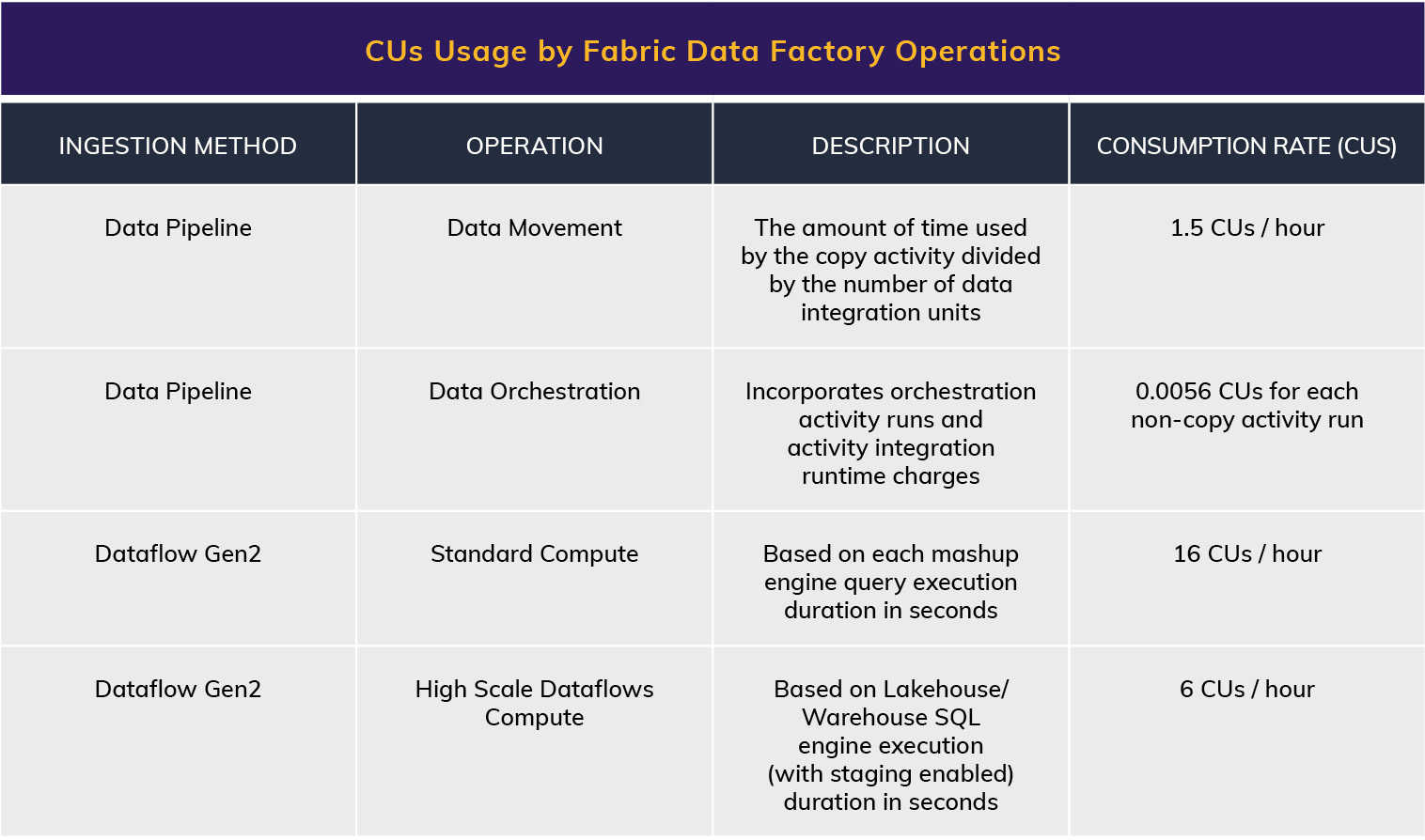
Table 5. CUs Usage by Real-Time Intelligence Operations
For real-time solutions, we recommend you have a minimum F4 capacity license SKU.
Synapse Data Science and Synapse Data Engineering
The underlying platform of Synapse Data Science and Synapse Data Engineering is a fully managed Apache Spark compute. This platform lets you perform large-scale data processing with ease.
In terms of CUs, two Spark vCores (virtual cores) equal one CU. And Fabric provides two spark compute configurations:
- Starter pools: These are fast default pools that provide an effortless way to use Spark on the Microsoft Fabric platform within seconds.
- Spark pools: A user defines these custom pools according to their resource utilization and configuration of the number and size of their nodes.
You only incur charges for these pools during the active, or run, state. Besides that, there are no itemized consumption charges, based on the operation performed by the Spark engine.
Power BI
Visualization and insights are crucial aspects of an analytical solution, and Fabric incorporates Power BI to meet this requirement. Power BI offers different licensing types, including free, Pro, Premium Per User, and Embedded.
As part of Fabric, eight CUs are equivalent to one Power BI vCore. Users included in the SKU of F64, and above capacity do not require any additional license to consume Power BI reports. Otherwise, one needs to have a Pro, Premium Per User, or Power BI individual trial license.
Many backgrounds and interactive operations consume CUs, from querying to rendering to refreshing the semantic model.
Copilot
Copilot is a generative AI-enhanced toolset that supports both data professionals in workflow development and business end-users in obtaining desired insights from undiscovered data questions and reports. Copilot works with Data Factory, Data Science, Data Engineering, Real-Time Intelligence, and Power BI workflows.
As it queries over the OneLake data layer, consumption is based on CUs, which depends on the number of tokens processed. Tokens represent small chunks of data or input. If you’re familiar with natural language processing, it can help to think of tokens as words. Approximately 1,000 tokens equate to about 750 words. As Table 6 illustrates, the consumption rate per 1,000 tokens varies based on input and output operations.

Table 6. CUs Usage by Copilot Operations
Copilot comes with an SKU of F64 and above capacity and should be enabled by the Fabric admin.
Monitor All Consumption
Managing your Microsoft Fabric cost and consumption of various offerings can be complex once solution building begins. To simplify this task, Fabric provides an app called the “Microsoft Fabric Capacity Metrics app.” This app monitors Microsoft Fabric capacities and tracks all CU consumption.
By providing detailed insights into resource usage, the app can help your organization make informed decisions, optimize capacity resources, reduce unnecessary spending, and ensure maximum efficiency. Regularly checking these metrics can help prevent unexpected costs and ensure you are using the right number of resources for your needs.
Conclusion
Understanding the core elements and consumption needs of different Microsoft Fabric use cases enables you to formulate a strategy for your solution requirements. You can choose from a wide variety of Fabric capacity licenses, starting with lower capacities and gradually scaling up as your business needs grow.
By regularly monitoring usage and adjusting capacity as needed, you can ensure your investment in Microsoft Fabric remains cost-effective and scalable for the long term.
Want more great content like this? Check out our blog.
Are you ready to move forward with a data strategy for your organization but aren’t sure where to start? Our Data and Analytics experts bring a tried-and-true approach for executing strategies into practical, pragmatic and actionable plans. Contact Us

