
Discover the benefits of fine-tuning large language models and retrieval-augmented generation. Learn how these powerful AI approaches can transform your organization’s data into precise, context-aware solutions.
AI is revolutionizing how businesses operate, make decisions, and automate complex tasks — driving efficiency and innovation across industries. However, one pressing question remains: How can organizations unlock the full potential of AI using their own data? Two powerful approaches can unlock this potential — fine-tuning large language models (LLMs) and retrieval-augmented generation (RAG).
Fine-tuning trains a large language model on domain-specific data to improve its responses, while RAG retrieves relevant information dynamically at runtime. In this blog, we’ll break down these two AI approaches, compare their strengths, and help you choose the right fit for your needs, empowering you to build smarter AI solutions. Let’s dive in!
What is Fine-Tuning LLMs?
Fine-tuning LLM means taking a pre-trained LLM and further training it on a smaller, more specific dataset to improve its performance on a particular task or domain. Specializing it for a niche use case makes it more accurate and relevant for that specific application.
Think of fine-tuning LLMs as training a general-purpose athlete to specialize in one sport. By focusing on specific data, it becomes an expert in a particular area, offering precise and relevant answers within that domain. For the LLM, this specialization results in:
- Precision: Becomes a domain expert, handling complex, specialized queries.
- Self-Sufficient: Once fine-tuned, the model operates independently without requiring external data.
- Tailored Results: Produces outputs that align with your specific goals.
- Task Specialization: Fine-tuning sharpens the model’s focus, allowing it to excel in tasks like diagnosing medical conditions or analyzing legal texts.
- High Performance for Narrow Domains: By tailoring the model to a specific dataset, fine-tuning ensures high accuracy and fluency in specialized tasks.
- Extended Lifespan for Legacy Systems: Fine-tuning enables existing models to adapt to new tasks or domains instead of creating a model from scratch.
How Fine-Tuning LLMs Works:
- Specialized Training Data: Feed the model examples from a specific area, like medical case studies or legal contracts.
- Tweaking Parameters: Adjust the model’s inner workings to make it an expert in that field.
- Mastery Achieved: The fine-tuned model performs tasks in its niche with unparalleled accuracy.
Real-life Use Cases for Fine-Tuning LLMs:
- Industry Chatbots: Provides expert customer support for banking or healthcare
- Creative Outputs: Writes in specific styles or generating niche content
- Specialized Reviews: Analyses technical documents or conducts detailed audits
What is Retrieval-Augmented Generation (RAG)?
RAG combines AI with external information sources in real time, allowing your AI system to provide up-to-date and context-specific responses by retrieving current data. This process enhances AI by ensuring responses remain accurate and relevant.
RAG enables accurate, personalized, data-driven solutions, making it particularly effective for real-time, context-aware applications.
Think of RAG as a delivery driver who doesn’t stock groceries but knows the fastest way to fetch them from the store. You get exactly what you need, fresh and on time.
RAG stands out because it’s:
- Always Current: It’s like getting news from a live feed instead of an old newspaper.
- Efficient: Doesn’t carry all knowledge internally, saving resources.
- Adaptable: You can add or update the data sources it relies on without retraining the model.
How RAG Works:
- Question Input: You ask a question or provide a query. The LLM processes the user query to frame the information needed.
- Search Stage: The system “Googles” the best sources, pulling up-to-date information from databases or documents. A retriever component searches an external database, knowledge base, or document store to fetch relevant pieces of text (e.g., passages or documents).
- Answer Creation: The model crafts a response tailored to your query using the retrieved data. The LLM synthesizes a response by combining the retrieved information with its internal reasoning capabilities.
Real-life Use Cases of RAG:
1. Customer Support Chatbots
Consider this scenario: A customer asks about the return policy for an item they purchased. Instead of giving a generic answer, the chatbot retrieves the latest return policy details from the website or internal documents and then generates a response that reflects the latest information.
How? A RAG-based system can be implemented in customer service to enhance chatbot responses. Instead of relying solely on pre-trained knowledge, the chatbot retrieves real-time information from a company’s knowledge base, product manuals, or FAQs to provide more accurate, context-specific responses.
2. Medical Diagnosis Assistance
Here’s another example: A doctor asks a system for the latest treatment options for a rare condition. The RAG model queries an up-to-date medical database and combines the retrieved information with its generative capabilities to provide a comprehensive answer that includes new treatments, potential side effects, and clinical trial results.
In healthcare, a RAG model can assist doctors or healthcare professionals by pulling the latest research, clinical guidelines, or case studies related to a specific medical condition. This ensures that the response incorporates the most recent and accurate information.
RAG vs. Fine-Tuning LLMs: A Side-by-Side Comparison
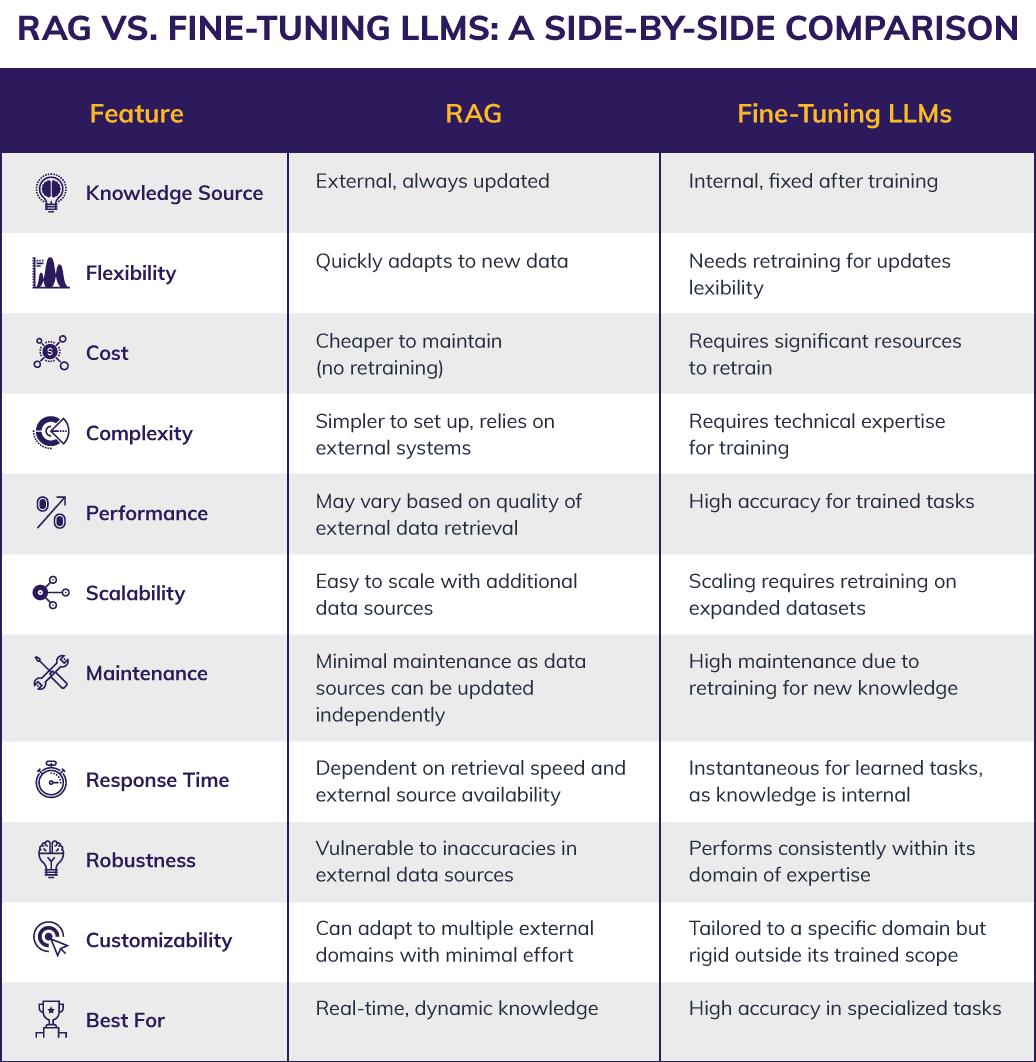
But which one is the right fit for your needs?
Imagine competing in a high-stakes trivia game with two ways to find the answer:
- Look it up in a trusted encyclopedia — precise and reliable (like RAG).
- Ask a genius with vast knowledge — intelligent but limited to what they’ve learned (like a fine-tuned LLM).
Which path do you choose?
Just like in this game, the choice between RAG and fine-tuning depends on the context, the information available, and the level of accuracy required. As AI continues to evolve, the ability to customize and optimize LLMs is shaping the next generation of intelligent applications. Organizations can enhance AI capabilities by leveraging RAG or fine-tuning an LLM, ensuring smarter, more relevant, and highly efficient solutions.
Choose fine-tuning LLMs if:
- Your project demands pinpoint accuracy in a stable, specialized domain.
- You want a self-contained expert model.
- Performance consistency is critical for your application.
Choose RAG if:
- You need constantly updated information.
- Cost and scalability are major concerns.
- Your project relies heavily on diverse, real-time data.
Can You Combine RAG and Fine-Tuning LLMs?
Absolutely! You train a model to specialize in finance regulations (Fine-Tuning LLMs) and then connect it to an up-to-date database of government policies (RAG). This hybrid approach delivers expertise and relevance, and, in some cases, combining both approaches can offer the best of both worlds, providing expertise and up-to-date information simultaneously.
Improve AI Initiatives With Fine-Tuning LLMs and Retrieval-Augmented Generation
Both RAG and fine-tuning LLMs are indispensable tools. You can tailor AI solutions that meet and exceed your unique needs by choosing the right approach – or even blending both.
Whether you require real-time, dynamic responses or specialized, high-precision outputs, these approaches offer the flexibility and accuracy to cater to various requirements. By using the appropriate strategy, you can unlock AI’s full potential, drive innovation, and stay ahead.
A well-crafted vision and strategy serve as your safeguard against failure and unlock AI’s full promise. But first, you need to know if your company is ready for AI.
Don’t get left behind in the AI revolution. We guide leaders through the disruption AI may cause to help you go from uncertain to excited about the potential of using AI. Ready to get started? Let’s Talk

