
3 Steps to Better Automation: Why the Understand, Simplify, Automate (USA) Framework Still Leads
Use the Understand, Simplify, Automate framework to keep your automation decisions grounded, whether you're deploying RPA, AI agents, or both.

Once you understand how RAG works and how to use it, you can help your organization use RAG to unlock deeper insights and get more out of your data.
Retrieval-augmented generation (RAG) integrates cutting-edge artificial intelligence (AI) capabilities with tailored information, empowering businesses to uncover nuanced insights, make informed decisions, and stay ahead in competitive markets.
In this article, we’ll delve into RAG and how it works, its core components and benefits, and practical strategies to integrate it into your business processes for measurable success.
Retrieval-augmented generation, or RAG, is a powerful blend of generative AI that combines the power of large language models (LLMs) with real-time, domain-specific data retrieval. This advanced AI framework bridges the gap between static knowledge bases and real-time information needs.
Let’s decode what its name — retrieval-augmented generation — actually means.
LLMs are a type of AI foundation model that are trained on huge datasets to generate a response to a user query. That’s the “generation” part of RAG.
Unfortunately, LLMs’ responses can be unpredictable because they have:
That’s where the “retrieval” and “augmented” parts of RAG come in. They solve these two issues.
RAG solves the issue of LLMs having no source of truth by retrieving relevant content from a verified and validated knowledge source. This eliminates hallucinations.
And RAG resolves the issue of the LLM responses being out-of-date by augmenting and updating new content to the knowledge base.
Thus, RAG uses LLMs while finding solutions for their shortcomings.
With that, let’s learn more about RAG’s core components and process.
RAG operates through a three-step process:
Now, let’s explore RAG’s architecture and how the retrieval and generative modules work together.
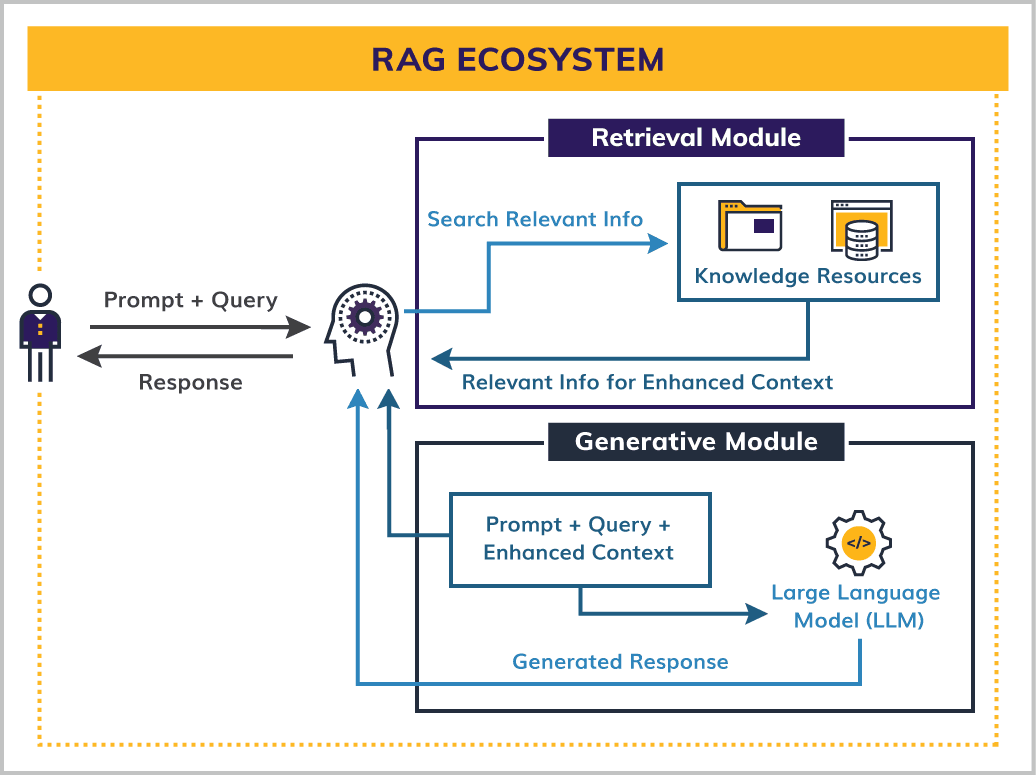
Figure 1: RAG architecture and process
The synergy between the retrieval and generative components enables RAG to dynamically adapt its outputs based on the specific needs of a query, making it a powerful tool for addressing complex, real-world business challenges.
The retrieval module is the main engine of the RAG architecture. To explore how it identifies and extracts relevant information from external knowledge sources, you first need to understand two key concepts: vector embeddings and vector databases.
These two components make it possible for the RAG retrieval module to identify and extract relevant information.
Vector embeddings are numerical representations of data points — like words, images or audio — that machine learning (ML) models can understand and process.
In RAG, an external knowledge source is converted into vector form and stored in a specialized database called a vector database. This database is designed to store, manage, and efficiently search through numerical representations of data.
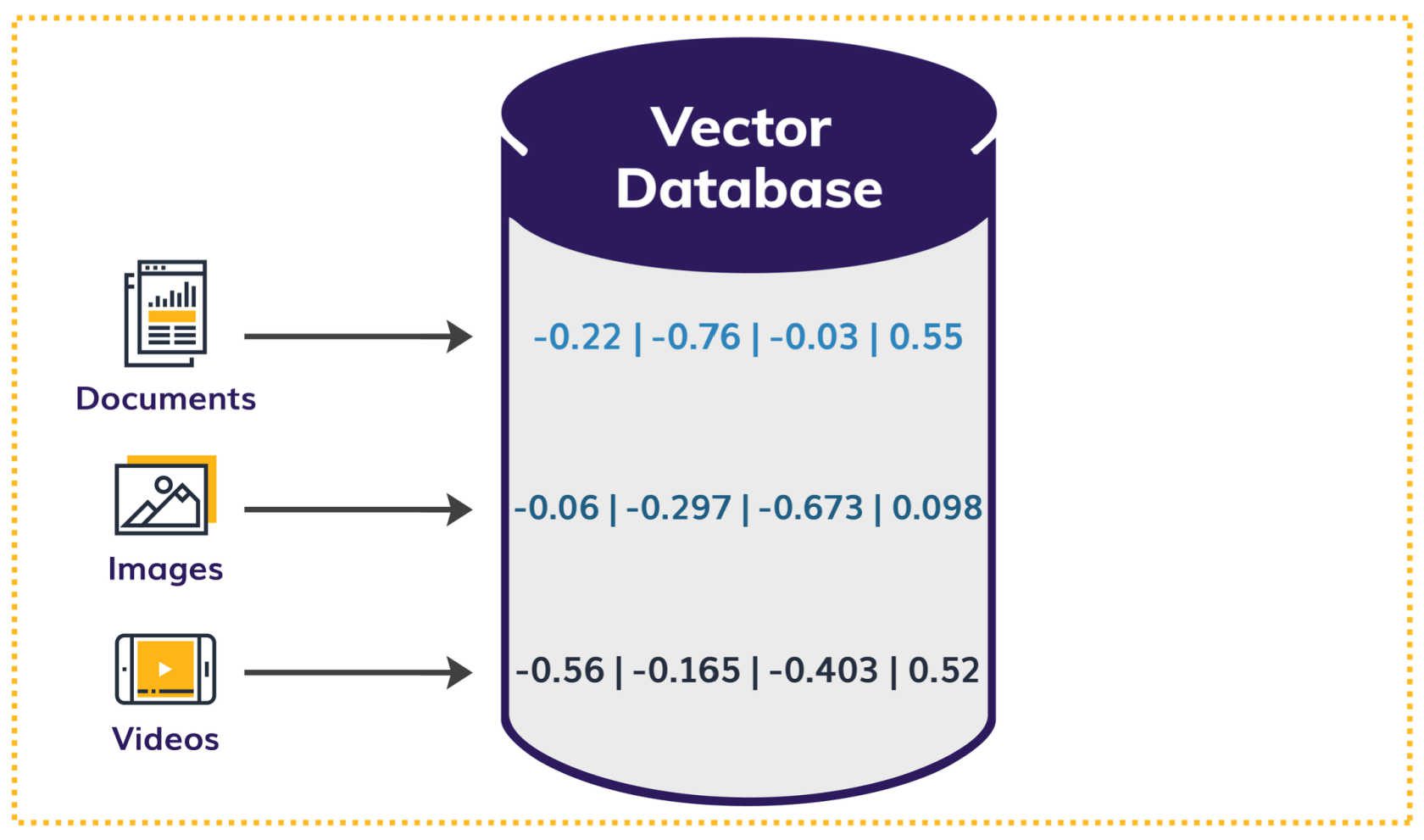
Figure 2: Embedding and vector database
Once you understand the vector database, you can visualize it as a high-dimensional space, where each value in a single vector represents a dimension like x, y, z, and so on, and forms a cluster (see Figure 3).
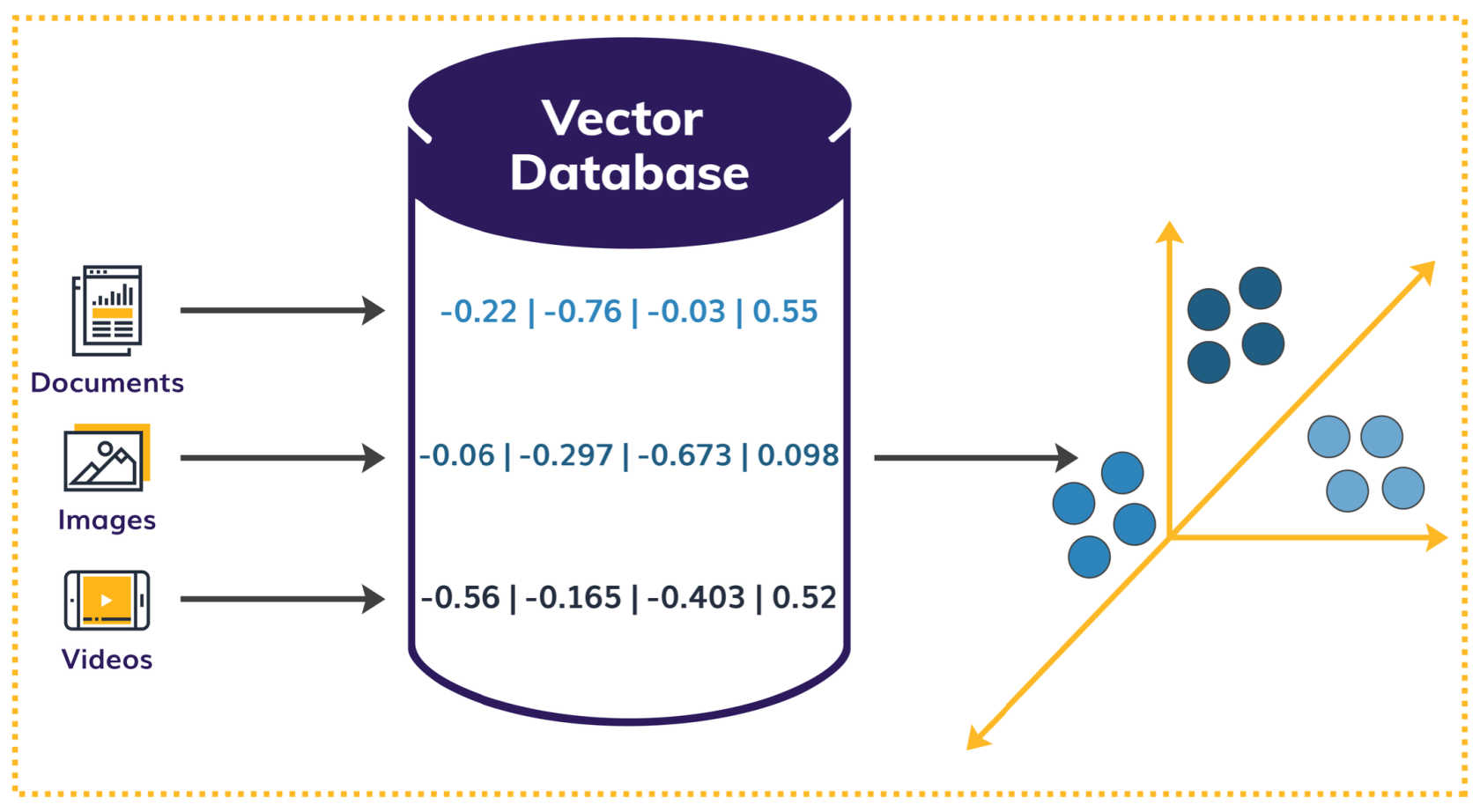
Figure 3: Visualize a vector database as dimensional space
Every user query is converted into its respective embedding value. RAG plots the user input’s vector values into the same dimension and extracts information that’s close to or part of the cluster that seems the most relevant to the user’s query (see Figure 4).
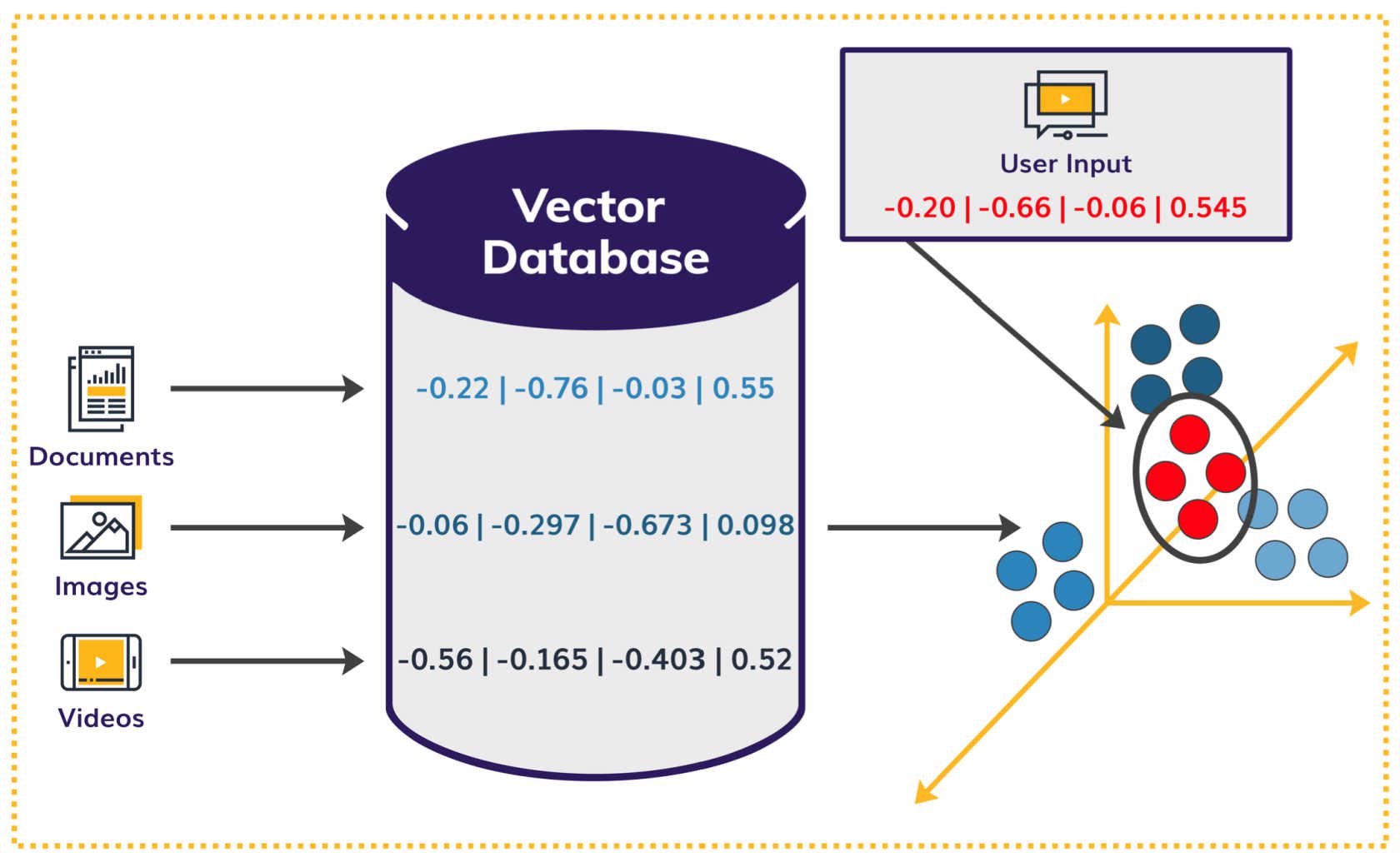
Figure 4: Plot user input’s vector values in dimensional space
This embedding process is performed by LLM embedding models. Your organization can create a custom embedding model in house, or you can use existing models from companies like OpenAI and DeepSeek.
Once you understand how RAG works and how to use it, you can help your organization use RAG to unlock deeper insights and get more out of your data.
To stay competitive amid constant change and information overload, your organization needs accurate, timely insights to carry out operations like responding to customer inquiries and strategize for future growth. RAG can help you do that.
Here are three key benefits RAG offers businesses:
RAG-powered tools empower business leaders with actionable insights by incorporating real-time data into their decision-making processes. For example, a retail company can use RAG to analyze shifting customer preferences and generate adaptive sales strategies.
With RAG, businesses can deliver hyperpersonalized experiences. A customer service chatbot, for instance, can retrieve a user’s transaction history and generate a tailored solution to their problem, improving satisfaction and loyalty.
RAG automates complex tasks such as summarizing documents and regulatory compliance checks. By reducing manual effort, RAG allows teams to focus on strategic priorities and innovate faster.
Companies in healthcare, finance and ecommerce are using RAG to gain a competitive edge. Whether they’re using RAG to provide physicians with real-time treatment recommendations or generate personalized product recommendations, businesses that use RAG smartly can outpace their competitors.
Although RAG has a lot to offer, your organization will need to overcome these challenges:
RAG’s ongoing advancements promise even greater capabilities as it evolves beyond text-based retrieval. It’s becoming multimodal and will integrate text, images, videos, audio, and structured data.
These advancements will enable AI models to fetch and generate responses using multiple formats and integrate with autonomous AI agents.
As businesses continue to evolve, the ability to access and use real-time information will become a cornerstone of success. RAG represents a pivotal step in this direction.
For business leaders, retrieval-augmented generation isn’t just an intriguing technological innovation — it’s a strategic imperative. By integrating real-time insights with advanced AI capabilities, RAG empowers organizations to make smarter decisions, enhance customer experiences, and streamline operations. Companies that invest in RAG now will position themselves to thrive in an increasingly competitive and data-driven world.
We strongly encourage forward-thinking businesses to explore how RAG can transform your operations and deliver sustainable growth in today’s dynamic market landscape.
This article was originally published on Medium.com.
Are you ready to explore how artificial intelligence can fit into your business but aren’t sure where to start? Our AI experts can guide you through the entire process, from planning to implementation. Talk to an expert


