
An IT disaster can cripple any business. In part two of this two-part series, we look at four common disaster recovery blueprints that you can utilize to align your disaster recovery plan.
In part one of this series, I outlined the prerequisites to building any good disaster recovery plan. The disaster recovery plan must meet the business recovery requirements, which we define as part of the business continuity planning process. Without this plan, you are throwing darts at a dartboard, not truly knowing what data and systems need to be recoverable at what recovery point objective to sustain the business and limit financial risk to the organization.
In part two of the series, I’ll walk you through four common disaster recovery blueprints that you can utilize to align your disaster recovery plan to the business requirements defined in your business continuity plan.
Need more tips, tools and techniques for business continuity?
AWS Disaster Recovery Blueprints
Assuming you deploy all IT applications within the Amazon Web Services (AWS) cloud, let’s look at four disaster recovery options to support your disaster recovery plan, which must support the defined recovery time objective (RTO) and recovery point objective (RPO). AWS enables you to cost-effectively operate your disaster recovery process using any of the following different scenarios. These are just examples of possible approaches to solving your DR needs. In some cases, variations or combinations of these approaches may be necessary to meet the RTO and RPO requirements outlined in your DR plan:
- Backup and Restore
- Pilot Light for Simple Recovery into AWS
- Warm Standby Solution
- Multi-site Solution
- Backup and Restore
In traditional on-premise environments, companies back up data to tape and send it off-site regularly. Or they back it up to a virtual tape library (VTL) and vault it to an alternate site. In the AWS cloud, taking snapshots of elastic block store (EBS) volumes and backups of Amazon RDS and storing them in Amazon S3 is a standard process for backup data, designed to provide 99.999999999 percent (11 9s) durability of objects over a given year.
Although this is the least expensive way, your recovery time will be the longest using this method. You will have to deploy a new EC2 and RDS instance and restore the backup data and configure the networking, security, database connectivity and any other custom configuration that needs to be updated for the application to function in the DR region. There are many commercial and open-source backup solutions that backup to Amazon S3.

2. Pilot Light
When using the pilot light method, the cost increases minimally, and you shorten the recovery time when compared to the backup-and-restore method. In the pilot light method, the core pieces of the system run and stay up to date in another region, where you will recover the rest of (or the remaining) applications.
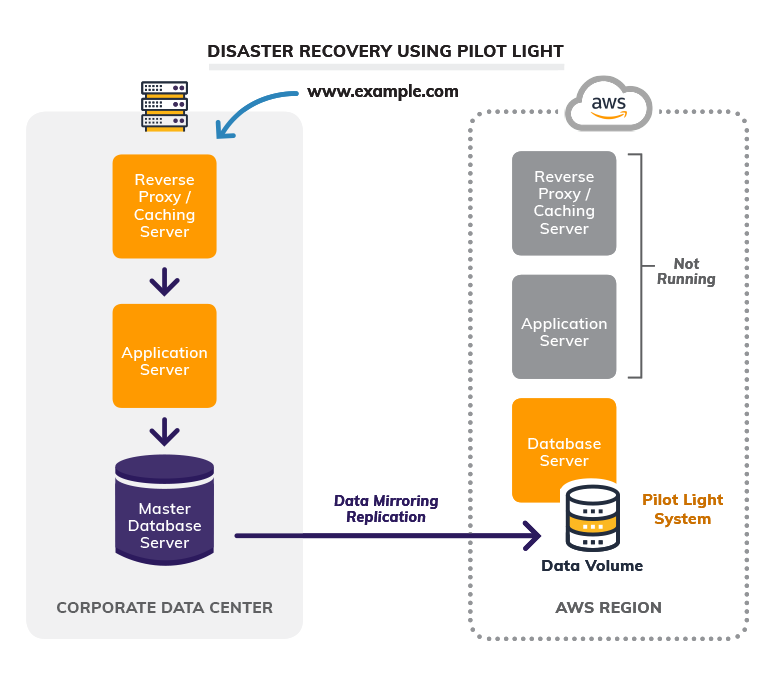
A recommended configuration is pre-building your load balancers with domain name service (DNS) names already registered in Route 53 and have your databases up and running with replicated data from your primary site. The server images back up, periodically, to AMIs and replicate to the DR region. During a disaster, you deploy the critical applications from AMIs in your pre-staged pilot light region. Then, you can update DNS records to reference the resources running in the DR region.
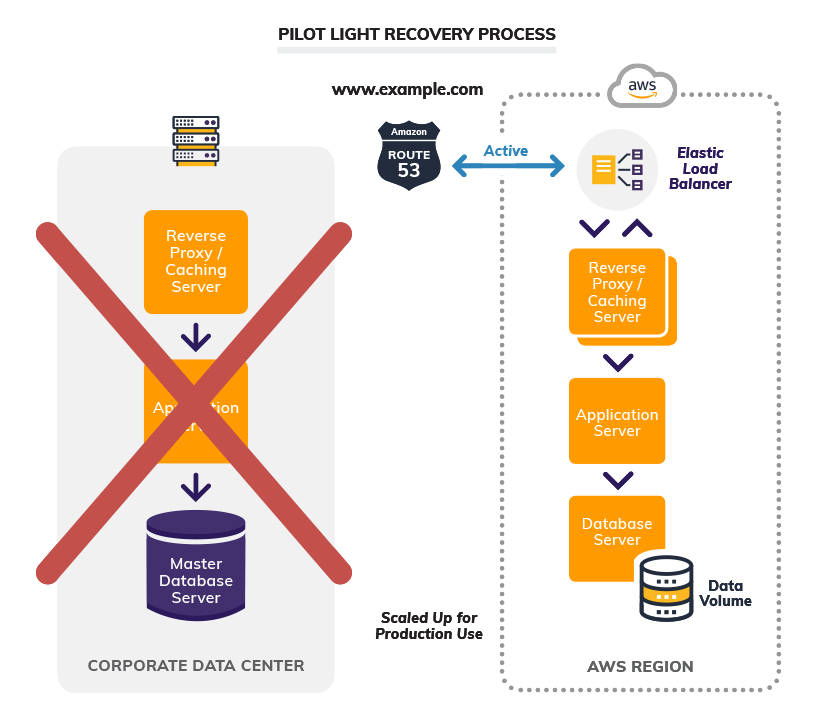
The image below shows the cutover process.
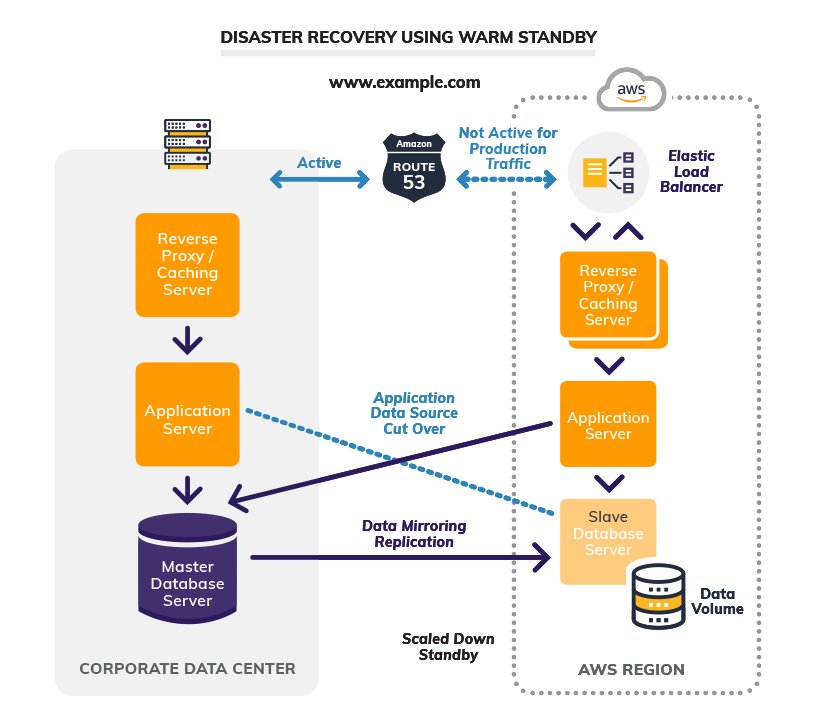
3. Warm Standby
Warm standby builds on top of the pilot light architecture. It further reduces the recovery time during a disaster because all critical services always run at a scaled-down capacity. This allows an almost immediate failover (very low RTO and RPO) during a disaster by simply updating DNS records to point to the warm standby resources but at a significant increase in operational costs. After a cutover to the warm standby DR site, you then scale up the infrastructure to support the full production workload.
The diagram below depicts the configuration of a warm standby DR site with data replication.
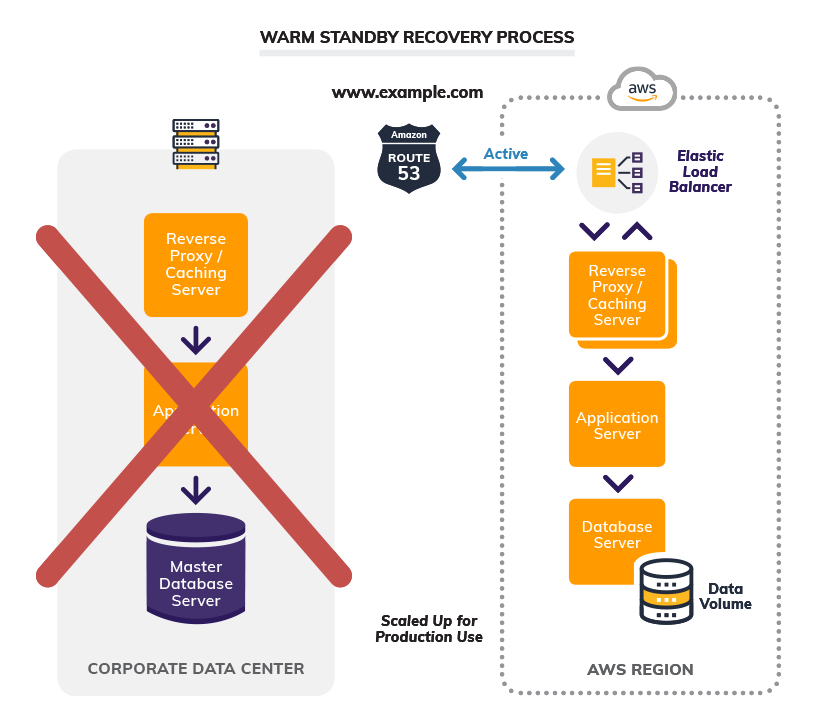
In case of a disaster, the cutover to the warm standby site looks like this:
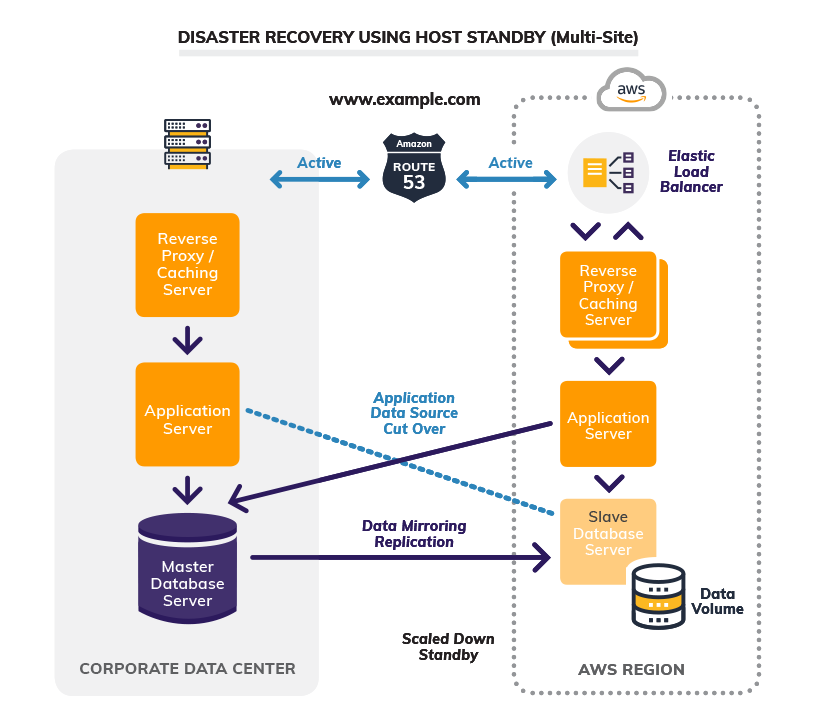
4. Hot Standby (Multi-Site)
To have the lowest RTO and RPO, the full application stack runs across both the primary site and DR site. In essence, you load-balance your application traffic across both sites using weighted DNS routing. Traffic goes to both sites at all times, replicates databases and maintains all applications and configuration in a production configuration across all platforms.
When the system detects a disaster, traffic automatically routes to the surviving site. By using auto-scaling, services scale up to support the full load at the surviving site. With multi-site, you can achieve zero RTO and RPO, but this is your most expensive DR option.
Below you can visualize an example hot standby architecture, where I configured Route 53 to route a portion of traffic to each site.
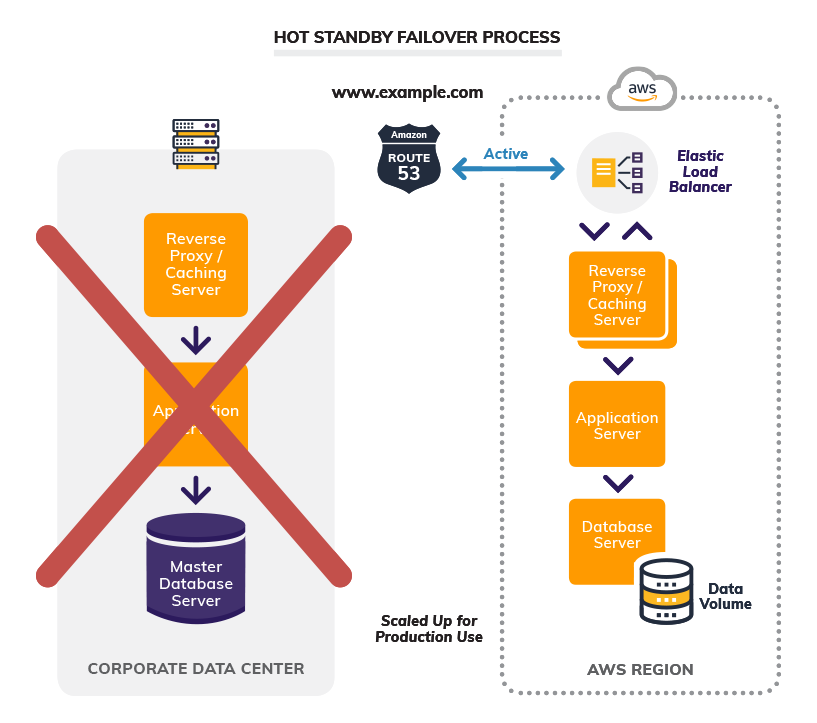
The figure below shows the effect of a disaster in a multi-site configuration. All traffic is routed to the surviving site and data you access from the replicated copy of the database. As traffic increases, auto-scaling deploys additional resources to support the increased load at this site.
Disaster Recovery Testing: Ensure Your DR Plan Works
When disaster strikes, you want to be confident that your business continuity plan works. You need to know all of the services and data required to run the organization are available within the defined RTO and RPO parameters. Disaster recovery testing is a multi-step drill of an organization’s DRP designed to assure you can restore your IT. systems if an actual disaster occurs.
Research shows the loss of IT functions in a disaster leads to organizational failure. For instance, according to a Spiceworks survey, eight percent of organizations that had an outage experienced data loss, and seven percent said their outages led to the failure of a product offering. Disasters don’t occur very often, but when they do, the effects can be devastating.
The main objective of your disaster recovery test (DRT) is to make sure that, in case a disaster does happen, the DR plan actually works. DR testing reveals whether the backup is truly as foolproof as you designed it be.
Ongoing testing is a necessity because changes to personnel, skill levels, and hardware and software architectures within an organization can impact the effectiveness of the DRP.
Restoring the Primary Production Site
The hope is when a disaster occurs, you can successfully recover the data and services in the failover region. It’s important that you work to recover your primary site after you move services so that you can roll back to the primary site.
Don’t overlook the need to continue your backup plan while services run in the DR site so that you can revert to the most current state and with up-to-date data sets. A good DR plan includes the procedures to fail back to the primary site smoothly. This includes keeping backups current while running in the DR site and having a plan to migrate back to the primary site.
Conclusion
In summary, I would like to stress that a business continuity plan should always precede a disaster recovery plan. The BCP will drive the specific recovery requirements (RPO and RTO) for each business application and each dataset. Once the business requirements are well-defined, i.e., the backup and recovery blueprints outlined in this blog, you can architect the appropriate backup and recovery process.